
خب بچهها، امروز میخوام براتون درباره یه ایده خیلی جالب تو دنیای هوش مصنوعی (AI) بگم. داستان از اونجا شروع میشه که چندتا دانشمند زرنگ اومدن و یه روش جدید برای بهتر جواب دادن هوش مصنوعیها به سوالای خیلی مهم و جدی، مخصوصاً سوالای پزشکی، امتحان کردن.
بیاید اول یه نکته رو روشن کنیم: مدلهای زبانی بزرگ مثل GPT-4 (مثلاً همون هوش مصنوعیای که جواب میده و حرف میزنه)، موقع جواب دادن به سوالا همیشه دقیق و یکنواخت رفتار نمیکنن. گاهی اوقات یه جواب خوب میدن، گاهی یه خورده پرت و پلا. دلیلش هم اینه که این مدلها شانسی (یا به قول دانشمندها “stochastic”) بعدی رو پیشبینی میکنن، یعنی همیشه همون جواب قبلی رو نمیدن! واسه همین اعتماد کردن به یه مدل تنها، مخصوصاً تو آزمونای حساس مثل USMLE (آزمون معروف پزشکی آمریکا)، خیلی ریسکه.
حالا این دانشمندها اومدن یه مدل جالب طراحی کردن که اسمش رو گذاشتن “شورای AI” یا Council of AIs. این یعنی به جای یه هوش مصنوعی، چندتا هوش مصنوعی (یا بهتر بگم چند تا نسخه GPT-4) دور هم جمع میشن، درباره سوالا با هم بحث میکنن و آخرش با کمک یه هوش مصنوعی دیگه که اسمش رو گذاشتن “مدیر جلسه” یا Facilitator AI (یعنی همونی که جلسه رو هماهنگ میکنه و همه رو سر جواب جمع میکنه)، به یه جواب مشترک میرسن.
این تیم باحالشون رو آوردن سراغ ۳۲۵ تا سوال آزمون USMLE. این آزمون سه مرحله داره:
- Step 1: سوالای علوم پایه پزشکی
- Step 2 CK: سوالای دانش بالینی و درمانی
- Step 3: سوالای آمادگی واسه طبابت مستقل و حرفهای
نتایجش چی شد؟ جالب اینجاست که شورای AI تو هر سه مرحله از یه مدل تکنفره خیلی بهتر عمل کرد. تو Step 1 تونستن ۹۷ درصد جوابا رو درست بدن، تو Step 2 حدود ۹۳ درصد و تو Step 3 هم ۹۴ درصد جواب درست داشتن. یعنی تقریباً همهش رو درست زدن! این درصدها واقعاً بالاست.
حالا گاهی پیش میاد که اوایلش همه Council با هم همنظر نبودن و جوابشون یکی نبود. اما با بحث و گفتگو بین هوش مصنوعیها (یعنی مدلها با هم حرف زدن و استدلال کردن)، تو ۸۳ درصد موارد حاضر شدن به یه جواب درست برسن! حتی جالبتر این که بیش از نیمی از جوابهایی که اکثریت رأی اول اشتباه داده بودن، بعد از بحث بین اعضای AI درست شد (۵۳ درصد). یعنی شورا خودش تونسته خطاهای جمعی خودش رو هم اصلاح کنه!
یه نکته آماری جالبتر اینه که احتمال این که جواب اشتباه اکثریت بعد از بحث تبدیل به جواب درست بشه، پنج برابر بیشتر بوده تا این که یه جواب درست اشتباهی بشه.
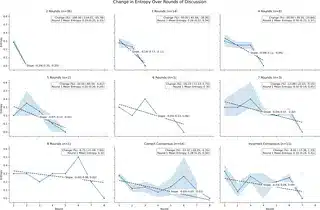
یکی دیگه از چیزای باحال این مقاله این بود که یه چیزی به اسم “entropy معنایی” (یعنی پراکندگی و گیجی تو جوابا) رو تونستن تا صفر برسونن! یعنی دیگه جواب آخر همیشه مشخص و بدون تردید باشه. این خودش نشون میده وقتی هوش مصنوعیها کنار هم کار کنن، میتونن همدیگه رو قویتر و جوابها رو دقیقتر کنن.
در واقع این مقاله اولین مدرک جدی رو نشون داد که اگه چندتا مدل هوش مصنوعی رو به صورت گروهی و با ذهن باز بذاریم کنار هم بحث کنن، نه تنها ضعیف نمیشن بلکه مثل یه تیم فوقالعاده عمل میکنن. چیزی که اولش یه ضعف به نظر میرسه (یعنی variablility یا ناپایداری جوابها)، آخرش تبدیل میشه به یه نقطه قوت که باعث میشه جوابا با فکر و دقت بیشتری شکل بگیرن.
خلاصه که این روشِ تیمی نه تنها واسه آزمون پزشکی کار داده، بلکه میتونه راه رو برای همکاری هوشهای مصنوعی تو بقیه زمینهها هم باز کنه؛ مخصوصاً جاهایی که دقت لازم و جواب درست خیلی مهمه. شمارو هم دعوت میکنم که مثل این هوش مصنوعیها، تو کار گروهی حرفهای بشین!
منبع: +



















