
خب بیاید یه موضوع خیلی مهم رو با هم مرور کنیم: فیبریلاسیون دهلیزی یا AF (که یه جور نامنظمی ضربان قلبه و میتونه باعث سکته یا نارسایی قلبی بشه) خیلی وقتها توی آدمها هست ولی خودشون خبر ندارن. اگر دکترها زودتر این مشکل رو بفهمن، میتونن جلوی کلی دردسر رو بگیرن. اما متاسفانه روشهای فعلی غربالگری، اونقدرها که باید خوب کار نمیکنن و حتی ممکنه کلی نفر رو جا بندازن!
خب اینجا پای یه تکنولوژی خفن به اسم ماشینلرنینگ یا یادگیری ماشین وسط میاد! ماشینلرنینگ یعنی مدلی که خودش با دادههای گذشته آموزش میبینه و یاد میگیره تا بتونه پیشبینی کنه یا تشخیص بده. حالا سوال اینه: این مدلها اگر بیان روی دادههای پزشکی که توی پروندههای الکترونیک بیمارها ثبت شده (EHR یعنی همون پرونده سلامتی دیجیتال) چقدر میتونن توی کلینیک یا درمانگاهها کمک کنن که چه کسی مشکل قلبی پنهون داره و چه کسی نه؟
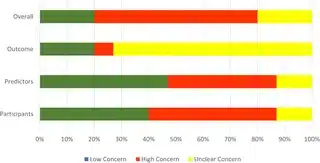
یه گروه از محققها تصمیم گرفتن حسابی این سوال رو بررسی کنن و به جای یه تحقیق فقط، اومدن یه بررسی نظاممند (یا همون Systematic Review) انجام دادن. یعنی رفتن و کلی مقاله و تحقیق رو از اولین روزهایی که این مدلها به پروندههای الکترونیک وصل شدن تا ماه مه ۲۰۲۳ زیر و رو کردن. نکته جالب اینه که کارشون رو طبق چندتا دستورالعمل معتبر جهانی انجام دادن (مثلاً PRISMA یعنی یه راهنما برای نقد و بررسی تحقیقات، Joanna Briggs هم یه موسسه معروف تو این کاره!) که نتیجهها حسابی معتبر بمونه.
اونا ۴۵۳۶ تا مقاله رو غربال کردن ولی فقط ۱۶ تا واقعا به دردشون خورد! توی این ۱۶ تا، بیشترشون یعنی ۸۷ درصدشون، مقالههایی بودن که با نگاه به گذشته و دادههای واقعی نوشته بودن (یعنی Retrospective cohort study). فقط یکی از اونها آیندهنگر بود (Prospective) و یکی هم تحقیق تصادفی و کنترلشده (Randomized Controlled Trial) بود. این یعنی هنوز خیلی از این مدلها تو دنیای واقعی به طور جدی امتحان نشدن.
جالب این بود که پرتکرارترین مدل ماشینلرنینگ هم “Random Forest” بود، یه مدل که در واقع چندین تصمیمگیرنده کوچیک داره و در کنار هم رای میدن (یعنی یه جور الگوریتم باحال که خوب بلده بین دادههای خیلی زیاد ارتباط پیدا کنه). حدود ۴۳ درصد مطالعات از رندوم فارست استفاده کرده بودن.
حالا نکته مهم! فقط ۲۵ درصد مطالعات مدل هاشون رو توی یه دسته داده خارجی امتحان کردن (به این کار میگن External Validation یعنی بررسی اعتبار مدل توی دادههای جدید و متفاوت از دیتای اصلی)، که معلوم شه واقعاً مدل رو هر آدمی جواب میده یا نه. این یعنی خیلی وقتها این مدلها فقط توی یه دیتای خاص جواب دادن و ممکنه جایی دیگه اصلاً کار نکنن.
نصف مدلها بهتر از روشهای رایج تشخیص بودن، چون .AUROC (که یه شاخص برای دقت مدل تو تشخیصه، هر چی به ۱ نزدیکتر بهتر!) توی این مدلها بین 0.71 تا 0.948 بود. این یعنی بعضیاشون خوب عمل کردن!
یه چیز جالب دیگه هم این بود که وقتی مدل ML رو با ابزارهای کلینیکی معمولی ترکیب کردن (تو سه تا مطالعه)، قدرت تشخیصشون خیلی بهتر شد. یعنی مدلها و دکترها وقتی با هم کار کنن عالیتر کار میکنن.
تو بعضی مدلها یه کشف باحال داشتن: مثلاً “نقرس” (Gout) که یه بیماری مفصلیه و معمولا به قلب ربطی نداره، ظاهرش توی مدلها معلوم شد احتمال AF رو بیشتر میکنه! یا این که تغییرات وزنی (BMI)، فشارخون و حتی داشتن سابقه نارسایی قلبی اگر به صورت دینامیک بررسی بشه (نه فقط یه بار اندازه گرفتن)، خیلی بهتر از مقادیر ثابت میتونن پیشبینیکننده باشن.
اماااا یه مشکل بزرگ هم وجود داره: بیشتر این مطالعات، خطر سوگیری یا بایاس (Bias یعنی نتایج تحت تاثیر عواملی غیر از واقعیت قرار گرفتن) خیلی بالا داشتن و فقط نیمیشون واقعاً نسبت به مراقبتهای رایج، ارزش اضافهای داشتن. تازه کلی پارامتر مهم هم هنوز به طور روتین تو درمانگاهها قابل دسترس نیست، پس کاربردشون محدوده.
در کل، این مدلهای هوش مصنوعی با پرونده الکترونیکی میتونن آینده تشخیص زودرس فیبریلاسیون دهلیزی رو رونق بدن، اما تا وقتی آدامه با داده واقعی تو جهان واقعی و درمانگاهها (نه فقط تو کامپیوتر) و با اعتبارسنجی درست اینها رو نسنجیم، نمیشه مطمئن بود.
نتیجه اخلاقی ماجرا: اگر دنبال پیشرفت واقعی این مدلها هستیم، باید اعتبارپروندههاشون رو بیرون از دیتابیس خودشون امتحان کنیم، توی مطالعات بالینی واقعی به کار بگیریم و فقط سراغ اون پیشبینیهایی بریم که واقعاً میتونیم تو پرونده دیجیتال به راحتی پیدا کنیم. دنیای آینده پزشکی جذابه، ولی نیاز به احتیاط و آزمون بیشتر داره!
منبع: +



















