
یه موضوع جالب پیدا کردم که میخوام براتون تعریف کنم. قضیه اینه که یه تیم محقق، با کلی آدم خفن از نقاط مختلف دنیا، اومدن سراغ این سوال که: “آیا مدلهای یادگیری ماشین (Machine Learning، همون برنامهها و الگوریتمهایی که با دادهها یاد میگیرن و پیشبینی میکنن!) واقعاً میتونن عادلانه چاقی، لاغری یا میزان چربی وسط بدن (بهش میگن central adiposity) رو تو قشرهای اقتصادی اجتماعی و گروههای مختلف طبقه اجتماعی و کاست توی هند پیشبینی کنن یا نه؟!”
اونا دست گذاشتن روی یه دیتاست خیلی خفن از هند به اسم “مطالعه طولی سالمندی هند” یا LASI که اطلاعات بیش از ۵۵ هزار نفر بالای ۴۵ سال رو داره، یعنی کلی داده از آدمهای واقعی. میخواستن ببینن که این الگوریتمهای معروف یادگیری ماشین – مثلاً Random Forest (یه مدل دستهبندی که شبیه ساختن جنگل از درختای تصمیمگیری عمل میکنه!)، XGBoost، Gradient Boosting، LightGBM (این دوتا هم مدلهای پیشرفته درختیان که خیلی تو حوزه AI استفاده میشن!)، شبکههای عصبی عمیق (Deep Neural Networks، یعنی مدلهایی که شبیه مغز کار میکنن!) و Deep Cross Networks (یه مدل پیچیده دیگه)، کنار مدل کلاسیکتر مثل رگرسیون لجستیک – واقعاً دقت و عدالت دارن یا نه؟!
خب روش کارشون این بود که ۸۰٪ از دادهها رو گذاشتن برای آموزش، ۲۰٪ رو برای تست. بعد با پارامترهای مختلف ارزیابی کردن، مثلاً AUROC (معیاری برای سنجش عملکرد مدل، هرچی بالاتر باشه بهتره)، دقت، حساسیت، ویژگی و صحت (sensitivity, specificity, precision). تازه اومدن همه اینا رو تو گروههای مختلف اقتصادی و کاستی هم بررسی کردن تا ببینن تبعیض اتفاق میافته یا نه. واسه بررسی عدالت، از چیزایی مثل Equalized Odds (یعنی مدل برای همه گروهها به یه نسبت درست یا اشتباه پیشبینی کنه) و Demographic Parity (یعنی مدل واسه همه گروهها به تعداد مشابه جواب مثبت یا منفی بده) استفاده کردن.
یادگیری ماشین معمولاً مشخص نمیکنه چرا یه تصمیم خاص گرفته، ولی اینا از SHAP استفاده کردن (Shapley Additive Explanations – یعنی روشی واسه فهمیدن اینکه کدوم ویژگیها تو پیشبینی بیشتر تاثیر داشتن)، تا بفهمن مثلاً قدرت دست، جنسیت یا محل سکونت چه نقشی تو مدل ایفا میکنه.
نتیجهها چی شد؟ مدلهای درختی مخصوصاً LightGBM و Gradient Boosting بهترین عملکرد رو داشتن — AUROC بالای ۰.۷۹ تا ۰.۸۴ (عدد بدی نیست!). وقتی اطلاعات اقتصادی و سلامتی رو وارد میکردن، پیشبینیها بهتر میشد. با این حال عدالتش کامل نبود: توی افراد از کاستهای پایینتر یا گروههایی مثل scheduled tribes (یعنی قبایل خاصی که معمولاً دسترسی کمتری به منابع دارن) مدلها ضعیفتر عمل میکردن. یعنی تو همون قشرهایی که معمولاً بیشتر نیاز دارن، مدلها اشتباه بیشتری داشتن!
با SHAP معلوم شد قدرت دست، جنسیت و محل زندگی مهمترین دلیل اختلاف پیشبینیها بودن. یعنی مثلاً اگه کسی زن باشه، دستش قوی باشه یا تو روستا زندگی کنه، مدل بیشتر براش خطا میزد یا کمتر درست پیشبینی میکرد.
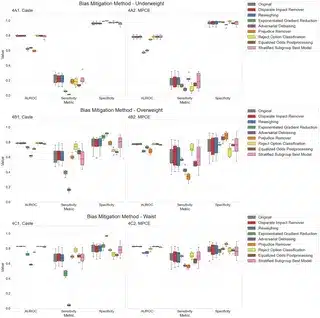
حالا برای رفع این بیعدالتیها، اومدن چند تکنیک ضد-سوگیری امتحان کردن. مثلاً Reject Option Classification (یه روش که مدل رو مجبور میکنن تو شرایط مبهم، تصمیمگیری رو متوقف کنه یا با احتیاط بیشتری جواب بده)، یا Equalized Odds Post-processing (در واقع سعی میکنن پیشبینیها رو بین گروهها منصفانهتر کنن). اینا تا حدی کمک میکردن اختلافات رو کم کنن، ولی بعضی وقتا باعث میشدن مدل کلاً دقتش بیاد پایین! بقیه روشها هم خیلی معجزه نکردن.
در کل، محققها نتیجه گرفتن که مدلهای یادگیری ماشین برای پیشبینی چاقی و ریسک چربی وسط بدن تو هند، ابزار باحالی هستن، ولی اگه دنبال عدالت و انصاف واقعی باشیم، باید بیشتر روشون کار کنیم و سوگیریهاشون رو بهتر در بیاریم. پس خلاصهاش این شد:هوش مصنوعی میتونه تو سلامت آدمها خیلی کمک کنه، ولی اگه ردپای بیعدالتی توش بمونه، نمیتونیم انتظار داشته باشیم تصمیمهاش واقعاً به نفع همه باشه. هنوز کلی کار مونده تا الگوریتمایی بسازیم که واقعاً بدون تبعیض و برای همه کار کنن!
منبع: +



















