
به دنیای پیچیده زنجیره فکری پیشرفته (CoT)، یکی از روشهای نوآورانه برای استدلال در مدلهای زبانی بزرگ، وارد میشویم. در این بررسی، سیر تحول CoT را از مراحل ابتدایی استدلال گام به گام تا تکنیکهای پیشرفتهتر، شامل رمزگشایی و رویکردهای مبتنی بر درخت، دنبال میکنیم. همچنین یاد میگیریم چگونه این تکنیکها میتوانند دقت و عمق خروجیهای مدل را بهبود بخشند.
درک زنجیره فکری (CoT)
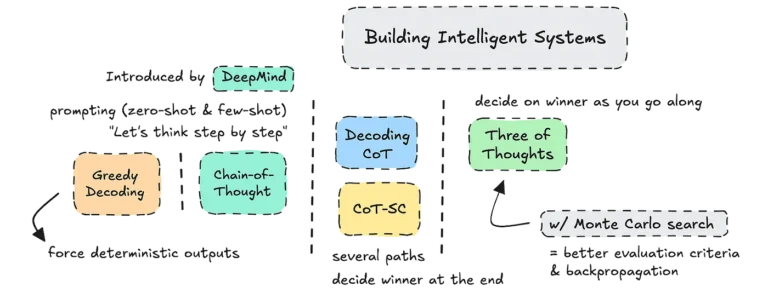
زنجیره فکری (Chain of Thought : CoT) روشی برای استدلال است. این روش به مدلهای زبانی بزرگ (LLM) کمک میکند تا فرآیند فکری خود را آشکار کنند. CoT که در سال ۲۰۲۲ توسط دیپمایند معرفی شد، مدلها را قادر میسازد مسائل پیچیده را به گامهای منطقی کوچکتر تقسیم کنند. این تقسیمبندی به دستیابی به پاسخهای دقیقتر منجر میشود. CoT با درخواست از مدلها برای “فکر کردن گام به گام” از تواناییهای استدلال ذاتی آنها بهره میبرد. این بهرهوری چه با رویکرد بدون نمونه (zero-shot) و چه با رویکرد کمنمونه (few-shot) امکانپذیر است.
به عنوان مثال، اضافه کردن عبارت “بیایید گام به گام فکر کنیم” به یک درخواست، میتواند عملکرد بسیاری از LLMها مانند ChatGPT و Claude و سایرین را به طور قابل توجهی بهبود دهد. از آن زمان، این رویکرد الهامبخش مجموعهای از تکنیکهای پیشرفته برای بهبود و تطبیق CoT با کاربردهای مختلف شده است.
تکامل تکنیکهای CoT
ساخت زنجیرههای استدلال
در ابتدا، CoT بر مسیرهای استدلال خطی تمرکز داشت. در این روش، مدل از ابتدا تا انتها در یک رشته واحد روی مسئله کار میکرد. اما پیشرفتهایی مانند سیستم بنجامین کلیگر، CoT را به سطح جدیدی رسانده است. این سیستم، استدلال را به چندین زنجیره تکراری تقسیم میکند. در این سیستمها، هر مرحله بر اساس مرحله قبلی ساخته میشود. این تکرار تا زمانی ادامه مییابد که مدل به پاسخ خود اطمینان پیدا کند.
برای مثال، در پاسخ به سوال “چند حرف R در کلمه Strawberry وجود دارد؟” این روش تضمین میکند که مدل قبل از نتیجهگیری، هر مرحله را با دقت بررسی کند. این رویکرد بهبود قابل توجهی در عملکرد، به ویژه با مدلهای بزرگتر مانند Llama 3.1 70B، در وظایف ریاضی نشان داده است.
تنظیم دقیق برای استدلال
تنظیم دقیق مدلهای کوچکتر روی مجموعه دادههای CoT برای نزدیک کردن تواناییهای استدلال آنها به مدلهای بزرگتر، مورد بررسی قرار گرفته است. اگرچه این مسیر امیدوارکننده است، اما نتایج فعلی هنوز پیشرفت چشمگیری نسبت به مدلهای پایه نشان ندادهاند. مخازن متنباز حاوی مجموعه دادههای CoT، منابع زیادی برای آزمایش فراهم میکنند. اما برای شکوفا شدن پتانسیل کامل تنظیم دقیق برای استدلال CoT، به مدلها و مستندات بهتری نیاز داریم.
فراتر از درخواست: تکنیکهای تولید پیشرفته
CoT اغلب به درخواست متکی است. اما روشهای جایگزینی مانند استراتژیهای رمزگشایی نیز وجود دارند. این روشها میتوانند خروجیهای مدل را بدون نیاز به دستورالعملهای صریح بهینه کنند. این روشها عبارتند از:
- رمزگشایی حریصانه (Greedy Decoding): این روش، مدل را مجبور میکند در هر مرحله محتملترین نشانه را انتخاب کند. این امر میتواند به پاسخهای قطعیتر منجر شود.
- نمونهگیری دما و Top-p: این پارامترها به ترتیب تصادفی بودن و تنوع انتخاب نشانه را کنترل میکنند. برای مثال، دماهای بالاتر خلاقیت را افزایش میدهند، اما ممکن است دقت را کاهش دهند. مقادیر پایینتر top-p، مجموعه نشانهها را به کاندیداهای با احتمال بالا محدود میکنند.
رمزگشایی CoT
رمزگشایی CoT، نوآوری مهمی در روشهای رمزگشایی است که توسط دیپمایند معرفی شده است. این تکنیک، نمرات اطمینان داخلی مدل را در چندین مسیر استدلال ارزیابی میکند. با انتخاب مسیری با بالاترین امتیاز احتمال، رمزگشایی CoT دقیقترین و مطمئنترین پاسخ را ارائه میدهد. این روش نتایج بهتری نسبت به رویکردهای سادهتر مانند رمزگشایی حریصانه نشان داده است.
ظهور روشهای مبتنی بر درخت
زنجیره فکری با خودسازگاری (CoT-SC)
CoT-SC چندین مسیر استدلال ایجاد میکند و سازگاری آنها را برای انتخاب قابل اعتمادترین پاسخ ارزیابی میکند. این رویکرد، بهبود ۱ تا ۸ درصدی را در وظایفی مانند استدلال حسابی نشان داده است.
درخت افکار (ToT)
ToT که توسط دانشگاه پرینستون و دیپمایند در اواخر سال ۲۰۲۳ معرفی شد، رشتههای استدلال را به صورت پویا در حین پیشرفت ارزیابی میکند. برخلاف CoT-SC که مسیرها را تنها پس از تکمیل ارزیابی میکند، ToT رشتههای کمامیدکننده را در میانه راه حذف میکند و منابع محاسباتی را بر روی راهحلهای عملی متمرکز میکند.
ToT را میتوان با جستجوی درخت مونت کارلو (MCTS) بهبود بخشید. MCTS، پس انتشار را برای اصلاح تصمیمات قبلی بر اساس اطلاعات جدید معرفی میکند. این ترکیب، امکان استدلال کارآمدتر و دقیقتر، به ویژه در حوزههای حساس که دقت بسیار مهم است، را فراهم میکند.
هزینه و کارایی در کاربردهای CoT
تکنیکهای پیشرفته CoT دقت را بهبود میبخشند، اما هزینههای محاسباتی و تأخیر را نیز افزایش میدهند. برای مثال، برخی از روشها به حداکثر هشت برابر قدرت پردازش بیشتر برای هر سوال نیاز دارند. این امر به هزینههای عملیاتی بالاتر برای برنامههایی مانند خدمات مشتری یا تصمیمگیری سازمانی منجر میشود.
در چنین مواردی، تنظیم دقیق مدلها برای گنجاندن مستقیم استدلال CoT میتواند هزینهها را کاهش دهد، اگرچه این همچنان یک حوزه تحقیقاتی فعال است. ایجاد تعادل بین دقت و کارایی، کلید تعیین زمان و نحوه استقرار تکنیکهای CoT است.
پیادهسازی عملی: رمزگشایی CoT
برای نشان دادن کاربرد عملی تکنیکهای CoT، میتوان یک سیستم رمزگشایی CoT را با استفاده از یک مدل متنباز مانند Llama 3.1 8B پیادهسازی کرد. این سیستم به صورت پویا پیچیدگی یک سوال را برای تعیین تعداد مسیرهای استدلال (k) مورد نیاز ارزیابی میکند. با استفاده از logits (نمرات اطمینان خام) و ایجاد چندین مسیر استدلال، سیستم مطمئنترین پاسخ را انتخاب میکند.
فرآیند پیادهسازی شامل موارد زیر است:
1. راهاندازی مدل: دانلود و ذخیره وزنها از Hugging Face برای دسترسی سریع.
2. تعریف پارامترها: پیکربندی تنظیمات رمزگشایی مانند مقادیر k و معیارهای ارزیابی.
3. توسعه API: ایجاد یک نقطه پایانی با استفاده از پلتفرمهایی مانند Beam.Cloud برای ارائه مدل و مدیریت درخواستهای کاربر.
نتیجه یک سیستم هوشمند است که میتواند پاسخهای دقیق با نمرات اطمینان ارائه دهد و پیچیدگی استدلال خود را بر اساس دشواری سوال تنظیم کند.
افکار نهایی
زنجیره فکری و انواع پیشرفته آن، نشان دهنده جهش بزرگی در قابلیتهای LLM هستند. از استدلال گام به گام ساده گرفته تا روشهای پیچیده مبتنی بر درخت، این تکنیکها مدلها را قادر میسازند تا با دقت بیشتری به مسائل پیچیده بپردازند. در حالی که چالشهایی مانند کارایی هزینه و مقیاسپذیری همچنان وجود دارد، CoT به عنوان پایهای برای مهندسی درخواست و استراتژیهای استدلال هوش مصنوعی در حال تکامل است.
با درک و پیادهسازی این چارچوبها، توسعهدهندگان میتوانند امکانات جدیدی برای ساخت سیستمهای هوشمند و انعطافپذیر متناسب با کاربردهای مختلف ایجاد کنند.
اگر به خواندن کامل این مطلب علاقهمندید، روی لینک مقابل کلیک کنید: towardsdatascience.com








")








")

