
یه موضوع جالب رو میخوام باهاتون درمیون بذارم: تا حالا به این فکر کردین که چطور میشه از اطلاعات پزشکی بیماران مختلف برای پیدا کردن مشکلات دارویی و عوارضشون استفاده کرد؟ خب، یه تیم توی آلمان (با کلی اسم و آدم باحال: Anna Maria Wermund و بقیه، با همکاری گروهی به اسم POLAR_MI) اومدن سراغ همین موضوع و حسابی باهاش کلنجار رفتن.
کل پروژه زیر نظر یه برنامه بزرگتر به اسم Medical Informatics Initiative Germany یا همون MII انجام شد – این برنامه یه جورایی میخواد باعث بشه همه بیمارستانهای دانشگاهی آلمان بتونن دادههای الکترونیک سلامت بیمارانشون رو راحت و استاندارد با همدیگه به اشتراک بذارن. این دادههای الکترونیک سلامت همون EHR (Electronic Health Record) هست – یعنی پروندههایی که توش کلی اطلاعات پزشکی الکترونیکی ذخیره میشه.
توی این حرکت، تمرکز اصلی روی بخشی به اسم POLAR_MI (سرواژهای از POLypharmacy, drug interActions and Risks – یعنی مصرف چند داروی همزمان، تداخل دارویی و خطراتش!) بود. هدفشون هم مشخص بود: اینکه بتونن عقبگرد کنن و با نگاه به گذشته متوجه بشن چه ریسکهایی برای بیماران بزرگسال بستری مرتبط با دارو وجود داشته.
حالا کاری که انجام دادن این بود که اومدن روی دو تا عارضه دارویی شایع تمرکز کردن: خونریزی گوارشی (GI bleeding – یعنی خونریزی در سیستم گوارش، مثلا معده یا رودهها) و هایپوگلیسمی دارویی (drug-related hypoglycaemia – همون پایین اومدن قند خون به خاطر دارو، که میتونه خطرناک باشه). هدفشون این بود که با اطلاعات اکترونیکی بیمارستانها (دادههای سال ۲۰۱۸ تا ۲۰۲۱) ببینن آیا اصلاً میشه این مشکلات رو شناسایی کرد؟ و اگه آره، با چه ریسکفاکتورهایی (یعنی عوامل خطری که باعث عوارض میشن) ارتباط دارن یا قابل پیشبینی هستن یا نه.
برای این کار یه تکنیک جالب استفاده کردن به اسم “تحلیل توزیعشده” یا Distributed Analysis؛ یعنی هر بیمارستان برای خودش اول کارای آماری رو انجام میده، بعدش نتایجِ همه رو با هم ترکیب میکنن. اینطوری اطلاعات بیمارا رو جابهجا نمیکنن – دادهها سرجاشون میمونن، ولی تحلیلها با هم جمعبندی میشن. تو زبان آماری به این جمعبندی میگن meta-analysis یا متاآنالیز (یعنی تحلیلِ تحلیلها – میدونم اسمش خنده داره!).
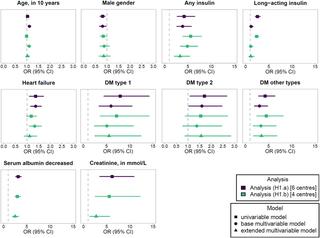
توی این پروژه، ده تا مرکز شرکت کردن. برا هر عارضه دو مدل ریاضی درست شد: مدل اول فقط اطلاعات دموگرافیک (مثلاً سنت و جنسیت)، تشخیص بیماریها و داروهای مصرفی رو میدید. مدل دوم یه مرحله هم پیشرفته تر بود: آزمایش خون و اینجور چیزها رو هم اضافه کردن. البته همه مرکزها نتونستن هر دو مدل رو اجرا کنن – مثلاً بعضیا دادههای آزمایشگاه رو نداشتن یا ناقص بود – واسه همین مجبور شدن گروههای مختلفی با دیتاهای مشابه کنارِ هم بذارن.
نتیجه جالب بود: تخمین زدن تقریباً ۱.۲ درصد بیماران خونریزی گوارشی پیدا کردن و تقریباً ۳ درصد هایپوگلیسمی ناشی از دارو داشتن. همین عددها واقعاً کمک میکنه بفهمیم چقدر این مشکلات شایع هستن.
یکی از چالشای اصلی نداشتن کامل همه دادهها بود – مخصوصاً نتایج آزمایشگاهی که خب بعضی مرکزها خیلی نداشتن یا یکدست نبودن. با این حال تونستن واسه هر دو عارضه تو چندتا مرکز مدل ریاضی بسازن و خوب هم جواب گرفتن.
یک نقطه قویِ مدلها این بود که شاخص AUROC یا همون area under the receiver operating characteristic curve (یه عدد که نشون میده مدل چقدر خوب میتونه عارضه رو پیشبینی کنه، مثلاً هرچی نزدیکتر به ۱ باشه یعنی بهتر) – اینجا تو همه مدلهای چندمتغیره بالای ۰.۷۰ بود. این یعنی مدلها واقعاً بدک نبودن و میشه رو همین روش حساب باز کرد.
در نهایت بچههای تیم رسیدن به این نتیجه که برای تخمین شیوعِ عوارض و ارتباط با فاکتورهای خطر، این روش توزیعشده واقعا جواب میده، مخصوصاً زمانی که داده بیمارستانها متنوع باشه. اما! باید حساب کار دستت باشه؛ یعنی باید سؤالات تحقیق رو با توجه به دادهها و زیرساخت هر بیمارستان طراحی کنی، وگرنه هیچی از آب درنمیاد.
در کل، این پژوهش نشون داد که اگه باهوش باشی و تحلیل آماری رو با شرایط هر مرکز سازگار کنی، میشه حتی بدون جمعآوری همه اطلاعات توی یه جا، مدلهای پیشبینی برای عوارض دارویی ساخت و استفاده کرد. واقعاً حرکت باحالی بود – هم از نظر پزشکی، هم دیتا ساینس!
منبع: +










