
خب بذارید یه ماجرای جدید و باحال رو براتون تعریف کنم که چطور هوش مصنوعی، مخصوصاً مدلهای زبانی بزرگ یا همون LLMها (که مثلاً ChatGPT خودش یکی از همیناست) دارن وارد بازی تصمیمگیری پزشکی میشن و حتی توی موضوع حساس مدیریت چاقی هم قالیچه خودشون رو پهن کردن!
اول از همه، فکر کنین کلی داروی جدید اومده که قراره به آدمایی که چاقی دارن کمک کنه، مخصوصاً اونایی که عمل جراحی متابولیک باریاتریک (یعنی جراحیهایی که باعث کم شدن وزن شدید میشه و همزمان مشکلات متابولیکی، مثل دیابت رو هم کنترل میکنه) انجام دادن یا میخوان انجام بدن.
این داروها از جمله GLP-1 receptor agonistها و همچنین dual incretin mimeticها هستن. اسمشون شاید یهکم ترسناک باشه، ولی مثلا GLP-1 agonistها داروهایی هستن که کاری میکنن بدن دیرتر احساس گرسنگی کنه و قند خون هم بهتر کنترل بشه.
حالا مشکل اینجاست که با وجود این داروهای جدید، هنوز یه راهحل دقیق و استاندارد برای اینکه کی باید دارو رو داد یا کی باید رفت سراغ جراحی، یا حتی آیا میتونیم اینا رو ترکیب کنیم یا نه، وجود نداره.
اینجا بود که انجمن جهانی جراحی چاقی (IFSO) اومد سال ۲۰۲۴ یه سری راهنمای جامع منتشر کرد که بگه چهجوری باید این داروها رو با جراحی متابولیک باریاتریک کنار هم استفاده کنیم. ولی خب مثلاً کی صد در صد مطمئنه که این راهنماها بینقصن؟
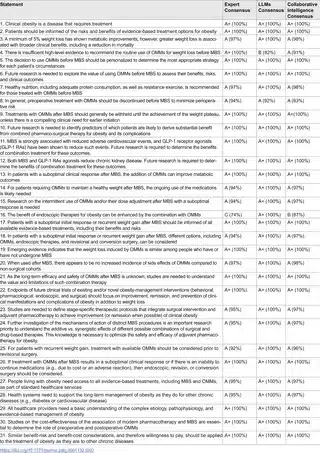
اینجا داستان جالبتر میشه: در یه تحقیقی که چند نفر متخصص بینالمللی (آقای کرمانسرای، پلینا سالمینن، گرهارد پراگر، و ریکاردو کوهن) انجام دادن، اومدن همون راهنماهای IFSO رو انداختن وسط و باهاش ۱۱ مدل هوش مصنوعی معروف رو به چالش کشیدن! مثلاً به هر مدل این پرسش رسید که: «با این توصیه موافقی یا مخالفی؟ دلیل علمیات چیه؟» جوابا خیلی سریع و با دلیل داده میشد، یعنی کاملاً بر اساس شواهدی که مدلها بلد بودن یا از دادههای آموزشیشون میدونستن.
حالا هر مدل باید درباره ۳۱ تا بیانیه IFSO نظر میداد (بیانیه یعنی همون توصیههای تخصصی). جواباشون هم صرفاً باید “موافقم” یا “مخالفم” میبود، بعلاوه یه دلیل کوتاه. بعد اومدن این جوابا رو جمعبندی کردن و یه چیزی به اسم “LLM Consensus” درآوردن؛ یعنی جمعبندی نظر همه مدلها.
حالا نکته جذاب اینجا بود که وقتی جوابای LLMها اومد، برای دو تا از این توصیهها، نمره تخصصیشون نسبت به چیزی که قبلاً IFSO گفته بود تغییر کرد! یعنی چی؟ یعنی:
۱. یکی از توصیهها که حسابی معتبر (سطح A+) بود، بعد از نظر LLMها یه کم پایین اومد و شد A، چون بعضی مدلها یهکم تردید داشتن و شواهد دقیقتری آوردن که شاید اونقدرا هم موضوع روشن نیست (در مورد اینکه کی باید قبل یا بعد جراحی از این داروها استفاده بشه).
۲. یکی هم که قبلاً نمره پایینتر (C) داشت، به خاطر حمایت کامل LLMها، بهتر شد و رفت تو دسته B. یعنی مدلهای هوش مصنوعی معتقد بودن ترکیب دارو و درمان اندوسکوپیک (یعنی درمانهای غیرجراحی که مثلاً با آندوسکوپی انجام میشه) ایده بدی نیست و ازش حمایت کردن.
باقی موارد هم (۲۹ تا از ۳۱ تا) تقریباً هیچ تغییری نکرد و همون نظر قبلی حفظ شد؛ که به این معنیه که LLMها، خیلی وقتا با نظر کارشناسا همنظر بودن.
در مجموع، میزان تطابق یا همانهمسویی بین حرفهای LLM و متخصصها حدود ۹۳٪ بود! این رقم خیلی بالاست و تقریباً نشون میده که کار با هوش مصنوعی، مخصوصاً اگر به کمک دکترها و سیستمهای تصمیمگیری هوشمند یا همون Collaborative Intelligence (که یعنی ترکیب توان مغز انسان با ماشین) انجام بشه، میتونه نتیجهها رو مطمئنتر و قابلاعتمادتر کنه. برای اندازهگیری دقیقتر میزان همفکری، از یه شاخص آماری به اسم کاپا (Fleiss’ κappa) استفاده کردن که هرچی نزدیکتر به ۱ باشه یعنی نظر مدلها باهم مشابهتره. اینجا میزان کاپا ۰.۸۱ (بین ۰.۷۴ تا ۰.۸۷) بود، یعنی واقعاً توافق زیادی وجود داشته.
ولی یه نکته جالب هم پژوهشگرا گفتن: اینکه LLMها با متخصصها موافق باشن، صرفاً معنیش این نیست که نظرشون صد درصد درست و بیطرفه. میگن شاید دلیلش این باشه که مدلهای هوش مصنوعی روی همون دادهها و مطالعاتی آموزش دیدن که کارشناسها هم بهش استناد میکنن. پس اگر جایی شواهد ناقص یا سوگیری باشه، مدل ممکنه بدون اینکه خودش بفهمه، همون رو تکرار کنه.
در نهایت اگه بخوام همهچی رو خلاصه کنم؛ تحقیق نشون میده همفکری دکترها با هوش مصنوعی باعث میشه حتی توی جاهایی که شواهد کمیابه یا مطمئن نیستیم، میتونیم دقیقتر تصمیم بگیریم. ولی باید بدونیم هوش مصنوعی یه ابزار کمکیه و جایگزین فکر و تجربه پزشکها نمیشه. هنوزم آدمها باید نقش اصلی رو بازی کنن و هوش مصنوعی فقط میتونه دستیار باهوششون باشه!
منبع: +



















