
خب بیاین امروز با هم یه موضوع جالب رو بررسی کنیم که کلی توی دنیای پزشکی سر و صدا کرده: تاثیر شرکت سازنده دستگاه ماموگرافی روی عملکرد هوش مصنوعی. (ماموگرافی یعنی همون عکسبرداری مخصوص برای شناسایی مشکلات پستان، مثلاً تشخیص زودهنگام سرطان سینه.)
یه تیم از دانشمندها اومدن بررسی کنن که اگه هوش مصنوعی رو با عکسهایی آموزش بدیم که فقط از یه نوع دستگاه خاص هستن (مثلاً دستگاه برند «هولوژیک» یا «جنرال الکتریک»)، ببینیم چقدر تو دستهبندی تراکم سینه زنها (breast density) دقیق عمل میکنه. تراکم سینه یعنی اینکه چقدر بافت چربی و غددی توی سینه هست.
برای این تحقیق، تیم حدود ۱۰ هزار و ۱۵۶ عکس ماموگرافی از خانمهای بین ۴۷ تا ۷۳ سال رو که سینهشون سالم بوده و هیچ نشونهای از سرطان نداشتن انتخاب کردن. این عکسها مال یه بانک اطلاعاتی به اسم OPTIMAM بین سالهای ۲۰۱۲ تا ۲۰۱۵ بوده. نکته باحال اینه که برای اینکه مطمئن باشن، از دادههای تایید شده توسط یه سیستم به نام Volpara هم استفاده کردن. (Volpara یه نرمافزار معتبر برای اندازهگیری دقیق تراکم سینهست.)
حالا موضوع اصلی این بود: سه تا مدل یادگیری عمیق یا Deep Learning بهشون آموزش دادن. (یادگیری عمیق یه شاخه خفن از هوش مصنوعیه که با شبکه عصبی مصنوعی کار میکنه و خیلی توی تحلیل تصویر قویه). این مدلها رو با سه تا دیتاست مختلف آموزش دادن: یکی فقط با دستگاه هولوژیک، یکی فقط با دستگاه جنرال الکتریک، و یکی ترکیبی که توش به طور مساوی عکس از هر سه برند معروف بود (هولوژیک، جنرال الکتریک و زیمنس). زیمنس هم یه برند خیلی معروف توی تولید دستگاههای پزشکیه.
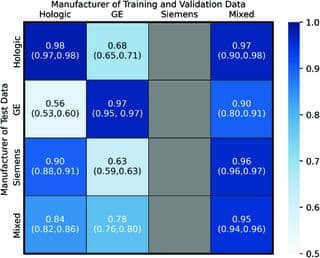
بعد، این مدلها رو روی چهار مجموعه عکس که قبلاً ندیده بودن تست کردن: ۱. فقط عکسهای هولوژیک، ۲. فقط جنرال الکتریک، ۳. ترکیبی از همه برندها، ۴. فقط زیمنس. برای مقایسه دقت مدلها، از معیار AUC استفاده کردن. (AUC یعنی مساحت زیر منحنی ROC که نشون میده مدل چقدر خوب میتونه بین تراکم سینه زیاد و کم تمایز بده. عددش هر چی به ۱ نزدیکتر باشه یعنی عملکردش عالیه.)
حالا نتیجه چی شد؟ اگه یه مدل رو فقط با عکسهای مثلاً هولوژیک آموزش بدی و براش همون عکسها رو تست کنی، نتیجه عالیه! مثلاً مدل هولوژیک رو اگر با دیتای خودش تست میکردن، AUCش میرسید به ۰/۹۸. برای جنرال الکتریک هم همینطور، AUC = ۰/۹۷. اما امان از وقتی که مدل رو با عکسهای دستگاههای دیگه تست کردن: دقت افتضاح شد! مثلاً مدل آموزشدیده با جنرال الکتریک، روی عکسهای هولوژیک فقط ۰/۶۸ و روی زیمنس فقط ۰/۶۳ نتیجه داد. عکس اینم صادقه: مدل هولوژیک روی جنرال الکتریک خیلی ضعیف عمل کرد (۰/۵۶) ولی روی زیمنس باز بهتر (۰/۹۰).
اما جالبترین قسمت داستان این بود که اون مدل ترکیبی که با عکسهای چند تا برند آموزش دیده بود (همهشون قاطی)، روی همه دیتاها بهترین کارکرد رو داشت و عملاً «سریعترین و باهوشترین» بود. نتیجه اینکه هرچی مدل رو با طیف وسیعتری از دستگاهها آموزش بدی، بهتر میتونه خودش رو با واقعیتهای مختلف تطبیق بده. به این میگن «بهبود توانایی گسترشدهی» یا Generalisation، یعنی مدلی که به راحتی گیر «تکمحیطی» نمیافته و تو شرایط مختلف هم خوب جواب میده.
از نظر آماری هم تو این پژوهش کار رو با ۹۵٪ اطمینان انجام دادن و برای مقایسه دقیقتر، یه ابزار خاص به نام Bayesian Signed Rank test استفاده کردن (این اسم یک روش پیشرفته برای مقایسه عملکرد چند مدل با هم دیگهست).
جمعبندی ماجرا اینه که اگه قراره هوش مصنوعی تو کلینیکها و غربالگری سرطان سینه به کار بره، باید حواسمون باشه دادههایی که بهش آموزش میدن از همه مدل دستگاههایی باشه که توی مراکز مختلف استفاده میشن. چون هرچی «تنوع دستگاه» بیشتر باشه، احتمال اینکه هوش مصنوعی بعداً تو دنیای واقعی گول نخوره و همه رو درست راهنمایی کنه بیشتر میشه. حتی اگه دستگاهها آپدیت یا عوض شدن، مدل هوش مصنوعی هنوزم کارایی خوبی از خودش نشون میده.
خلاصه، هوش مصنوعی هم مثل خود ما، هرچی دنیای اطرافش پیچیدهتر و متنوعتر باشه، باهوشتر میشه!
منبع: +















