
امروز اومدم براتون درباره یه موضوع خیلی جالب حرف بزنم: استفاده از هوش مصنوعی واسه تشخیص یه چیز مهم به اسم پاپیلودما! حالا حتماً میپرسین پاپیلودما دیگه چیه؟ بذار براتون توضیح بدم: پاپیلودما یعنی ورم سر عصب بینایی چشم، که معمولاً نشونه اینه که فشار داخل مغز رفته بالا. حالا این داستان چرا مهمه؟ چون وقتی این فشار بالا میره، میتونه علامت بیماریهای جدی توی مغز باشه.
توی خیلی از جاها، مخصوصاً جاهایی که امکانات پزشکی کمه، گرفتن عکس مغزی (مثل ام آر آی) ممکن نیست یا کلی هزینه و دردسر داره. اما خبر خوب اینه که دانشمندا اومدن سراغ هوش مصنوعی – همون AI که هر روز داریم بیشتر ازش میشنویم – و دارن باهاش عکسای چشم افراد رو بررسی میکنن تا ببینن سر و کله پاپیلودما پیدا شده یا نه.
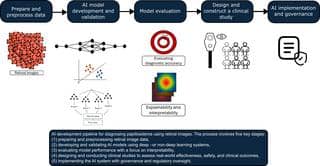
حالا تو این مقاله، گروهی از پژوهشگرا اومدن و یه بررسی کلی روی مطالعاتی که تا حالا درباره کمک گرفتن از هوش مصنوعی توی تشخیص پاپیلودما انجام شده رو انجام دادن. یعنی رفتن سراغ چندتا پایگاه داده مهم (Ovid MEDLINE، Embase، Web of Science، و IEEE Xplore) و مطالعات مرتبط رو جمع و جور کردن.
اونا برای اینکه ببینن هر تحقیق چقدر دقیق کار کرده، از یه چکلیست تخصصی مخصوص هوش مصنوعی تو تصویربرداری پزشکی استفاده کردن (یه جور لیست برای کنترل کیفیت تحقیقات). بعدش هم یه روش پنجتایی خلاقانه به اسم SMART برای شناسایی مواردی که ممکنه توی بررسیها باعث خطا و بایاس بشه، به کار بردن. بایاس یعنی همون جهتگیری یا انحراف نتایج به خاطر مشکلات تو طراحی یا اجرای مطالعه.
کلا ۱۹ تا سیستم «دیپ لرنینگ» (Deep Learning که یه مدل خیلی پیشرفته یادگیری تو هوش مصنوعیه و میتونه از کلی داده، خودش چیز یاد بگیره) و ۸ تا هم سیستم غیر دیپ لرنینگ رو وارد مقایسه کردن. جالب اینجاست که تو قسمت آموزش (Training) تعداد عکسای سالم معمولاً بیشتر از عکسای مشکلدار بود: مثلاً وسطیِ تعداد عکسای دیسک سالم ۲۵۰۹ تا بود ولی عکسای پاپیلودما فقط ۱۲۹۲ تا. در بخش تست هم اوضاع مشابه بود. این یعنی دادهها یه کم بالانس نبودن!
از لحاظ اطلاعات جمعیتشناسی، بیشترین چیزی که گزارش میشد فقط سن و جنسیت بود، اونم فقط تقریباً توسط یکسوم پژوهشها. پس کلی داده مهم دیگه، اصلاً گزارش نشده بود.
نکته اساسی اینه که فقط ۱۰ تا از اون همه مطالعه، سیستمهاشون رو به صورت بیرونی یا External Validation امتحان کردن. External Validation یعنی مدل هوش مصنوعی رو روی دادهها یا بیماران واقعی دیگهای که توی آموزش مدل نبودن تست کنن تا ببینن واقعاً جواب میده یا نه.
حالا، حساسیت و اختصاصیت چی بود؟ حساسیت یعنی مدل چقدر خوب موارد پاپیلودما رو پیدا میکنه. اختصاصیت هم یعنی چقدر خوب میتونه موارد سالم رو شناسایی و جدا کنه. اینجا حساسیت مدلها حدود ۸۷٪ (با بازه اطمینان ۷۶ تا ۹۳ درصد) بود و اختصاصیت اونم نزدیک ۹۰٪ (بازه ۷۴ تا ۹۷ درصد). یعنی عددهاش نسبتاً بالان!
ولی! باید حواسمون باشه چون کیفیت بعضی گزارشا پایین بود، دادهها گاهاً جهتدار انتخاب شدن و مدرک زیادی برای اینکه این نتایج تکرارپذیر باشن، وجود نداره. خلاصه، الان استفاده از هوش مصنوعی برای این ماجرا خیلی امیدوارکننده نشون میده، مخصوصاً برای جاهایی که اسکن و تجهیزات گرون نداریم. ولی هنوزم نیاز داریم مدلها رو با مجموعه دادههای خیلی بزرگتر و متنوعتر، تو محیطهای درمانی مختلف امتحان کنیم. اون موقع میشه واقعاً بهش به عنوان یه ابزار کمککننده حساب کرد.
خلاصه جای امید هست، ولی باید بیشتر روش کار بشه تا قابل اعتماد و استفاده تو واقعیت آینده بشه!
منبع: +



















