
خب بچهها، بیاید یه موضوع خفن رو با هم بررسی کنیم: اینکه چطور دارن با هوش مصنوعی (همون AI خودمون) به کمیتههای بررسی اخلاقی تحقیقات پزشکی در ژاپن کمک میکنن! این یه مطالعه آزمایشیه (Pilot Study)، یعنی تازه اول راهه، اما خب نتایج جالبی داشته.
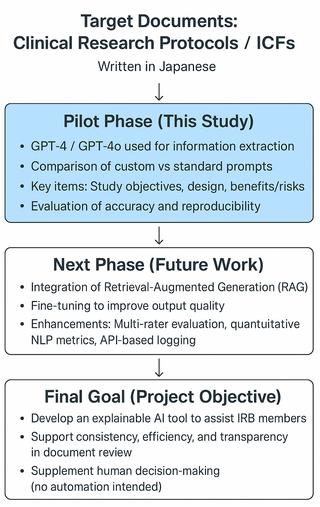
ماجرا از این قراره که چند تا محقق ژاپنی (یاسوکو فوکاتاکی، واکاکو هایاشی و دوستانش!) دارن یه ابزار هوش مصنوعی درست میکنن تا به ارزیابی اخلاقی اسناد تحقیقات بالینی که به زبان ژاپنی نوشته شدن کمک کنه. دقت کن که اونا گفتن این ابزار نمیخواد متن بنویسه یا متن پیشنهاد بده—فقط میخواد موقع بررسی اخلاقی، اطلاعات مهم و حیاتی رو سریع بیرون بکشه. 🤖
حالا اوکی، از چه هوش مصنوعی استفاده کردن؟ اساس کارشون روی مدلهای Generative AI بوده—یعنی همون هوش مصنوعیهایی که میتونن خودشون چیز تولید کنن، مثل ChatGPT. اینجا از دو مدل معروف GPT-4 و نسخه بهروزتر اون یعنی GPT-4o استفاده کردن.
برای کارشون یه سری GPT اختصاصی (Custom GPT) ساختن، و در واقع GPTها رو با سوالات و دستورالعملهای مخصوص ژاپنی آموزش دادن. منظور از Custom GPT اینه که شما میتونی خودت یه نسخه ChatGPT بسازی که مخصوص کار خودت باشه—اینجا هم این کار رو کردن.
سوال اصلی این بوده که این مدلها “میتونن بهدرستی اطلاعات اخلاقی مهم رو از اسناد تحقیقاتی پیدا کنن یا نه؟” مثلاً هدف تحقیق چیه، طراحی پژوهش چیه (یعنی مثلاً از چه روشی دارن استفاده میکنن) و اینکه چه ریسکها و مزایا و توضیحاتی واسه داوطلبین شرکتکننده وجود داره.
خب بریم سر اصل نتیجهها:
– اول اومدن GPT-4 و GPT-4o رو با هم مقایسه کردن، با همین GPTهای سفارشی. بعدش هم GPT-4o رو گرفتند و باهاش تستهای بیشتری انجام دادن: یک بار با دستورهای ژاپنیِ مخصوص و یه بار هم با فرمان معمولی.
– نتیجه جالب: GPT-4o تونست توی پیدا کردن هدف و پیشزمینه تحقیقات توی ۸۰٪ موارد با نظر کارشناس موافق باشه (یعنی درست حدس زده)، و توی استخراج طراحی پژوهش ۱۰۰٪ دقیق بود! 😮 تازه هر بار که کار رو تکرار میکردن، جواباش تقریباً یکی میموند (یعنی قابل تکرار بودن نتایجش بالاست).
– و متوجه شدن اون GPTهایی که با دستورالعمل و عبارتهای سفارشی ژاپنی آماده شدن، خیلی دقیقتر و ثابتتر جواب میدن تا اینکه فقط یه سوال معمولی بدی بهش.
حالا کلاً چی میخوان بگن؟ این تحقیق نشون میده که این جور هوش مصنوعیها میتونن به داوریهای اولیه کمیتههای اخلاقی (Pre-IRB review) کلی کمک کنن. حالا IRB همون کمیته بررسی اخلاقی تحقیقات پزشکیه—یعنی یه تیم که میشنن بررسی میکنن تحقیق شما اخلاقیه یا نه.
نکته مهم: قراره این ابزار جایگزین انسان نشه یا خودش به طور اتومات تصمیمگیری کنه! هدف اینه که به اعضای کمیته کمک کنه اطلاعات سریعتر و دقیقتر جمع کنن. یعنی یه دستیار هوشمند برای تصمیمگیری بهتر.
یه سری محدودیت هم داشته این مطالعه:
– هیچ داده مرجع مطلقی (Gold Standard Reference Data) نداشتن، یعنی نمیتونن دقیق بگن جواب AI کاملاً درسته یا نه.
– فقط یه نفر کار رو ارزیابی کرده، پس شاید قضاوت شخصی بوده باشه.
– بررسی اینکه بقیه آدمها هم اگه تکرار کنن به همین نتیجه میرسن، نشده (همون Inter-rater reliability).
– و در آخر، حتی بهترین AI هم نمیتونه چیزهایی مثل بازدید میدانی از پژوهشها یا صحبت رو در رو با تیم تحقیق رو جایگزین کنه.
در کل، این تیم یه قدم مهم برداشته برای اینکه شاید تو آینده بتونن ابزارهایی بسازن که پیش از اینکه اسناد بره پیش کمیته اخلاق، AI کمک کنه اطلاعات مهم دربیاد. دارن هم داده پایه جمع میکنن برای مراحل بعدی: مثلاً روشهایی مثل Retrieval-Augmented Generation (یعنی مدل هایی که بتونن جواب رو با توجه به اطلاعات و اسناد جدید بهتر تولید کنن!) یا Fine-tuning (یعنی آموزش بیشتر AI برای کار خاص) رو هم تو برنامه دارند.
خلاصه اگه علاقه داری یا تو حوزه تحقیقات پزشکی کار میکنی، این ماجرا رو دنبال کن! احتمالاً هوش مصنوعی قراره تو بررسی اخلاقی تحقیقات نقش پررنگتری پیدا کنه، البته فقط به عنوان یه کمککننده باحال، نه یه داور نهایی.
منبع: +










