
اگه تا حالا امتحان پزشکی یا رزیدنسی تخصصی داده باشی، حتماً میدونی که طراحی سوالای باکیفیت چقدر چالشبرانگیزه. درست کردن امتحان درست و حسابی برای تخصصها مثل طب خانواده، واقعاً هم وقت میبره، هم گرون درمیاد و هم نیاز به کلی آموزش داره. حالا بیاید ببینیم ChatGPT-4 تو این داستان چه کمکی میتونه بکنه!
توی یه تحقیق جدید، اومدن بررسی کردن که ChatGPT-4 (همین هوش مصنوعیه که خیلیا سرش بحث دارن!) واقعاً میتونه تو ساختن سوالای امتحان تخصصی طب خانواده کمکمون کنه یا نه. منظور از طب خانواده همون رشته تخصصیه که پزشکاش به مشکلات عمومی و اولیه مردم میپردازن.
پژوهشگرها یه روش نسبتاً استاندارد درست کردن برای تولید سوالای تستی (MCQ یعنی Multiple Choice Question، همون سوالای ۴ گزینهای خودمون!) تو امتحانهای بعد از فارغالتحصیلی. اومدن و سوالا رو تو ۴ دسته جدا امتحان کردن:
- سوالهایی که کاملاً توسط انسان نوشته شدن.
- سوالایی که ChatGPT-4 بر اساس نمونههای انسانی کپی کرده (یعنی سعی کرده مثل سوالای اصلی بنویسه).
- سوالای کاملاً جدید و ابتکاری که ChatGPT-4 خودش خلق کرده.
- سوالایی که کار ChatGPT-4 بوده ولی بعدش یه آدم خبره ویرایششون کرده.
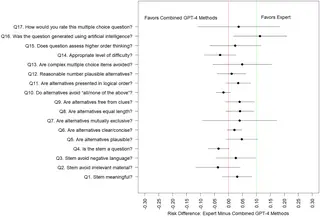
برای این ارزیابی ۸ تا متخصص طب خانواده جمع کردن تا این سوالها رو تو ۱۷ تا معیار مختلف کیفیت، امتیاز بدن. یعنی مثلاً نگاه کنن ببینن سوالا چقدر کاربردیان، قابل فهمان یا ذهن رو به چالش میکشن؟ (Higher-order thinking یعنی سوالایی که فقط حفظیات نیست و باید واقعاً فکر کنی حین جواب دادن!)
جالب اینجاست که هم سوالای انسانی و هم سوالایی که ChatGPT-4 تولید کرده بود، کیفیت بالایی گرفتن و ذهن رو حسابی به چالش میکشیدن. اما یه نکته بامزه این بود که متخصصا خیلی راحتتر میتونستن تشخیص بدن کدوم سوال رو هوش مصنوعی نوشته و کدوم رو یه آدم. یعنی سوالای ساختگی توسط انسان، کمتر “ماشینی” به نظر میاومدن.
از لحاظ فنی، یکی از نکات مهم اینه که تو بعضی از معیارها، سوالای ChatGPT-4 به هیچ وجه از سوالای انسانی بدتر نبودن (حالا اصطلاح Non-inferior یعنی از لحاظ علمی قابل قبول و کمتر از ۱۰ درصد اختلاف نسبت به کار انسان)، ولی برتری خاصی هم نداشتن نسبت به سوالای انسانی.
نتیجه نهایی این شد که ChatGPT-4 میتونه سوالای تستی کاملاً باکیفیت تولید کنه و حداقل تو بعضی معیارها، واقعاً قابل قبوله. پس این مدلهای زبانی خیلی بزرگ (Large Language Models یا همون LLMs، که یعنی هوش مصنوعیهایی که کلی متن خوندهن و میتونن متن جدید بسازن)، میتونن تو ساختن و حتی ارزیابی محتوای آموزشی کمک بزرگی بکنن. این کمک یعنی صرفهجویی تو وقت و هزینه—و البته شگفتزده شدن از هوش این ماشینها!
در کل، این ماجرا نشون میده که آینده آموزش پزشکی و امتحانها ممکنه حسابی متحول بشه! ولی هنوز هم چک کردن کارهای هوش مصنوعی توسط آدم خبره مهمه تا یه وقت سوتی ندیم!
منبع: +



















