
خب بچهها رو واکسینه کردن هر سال جون میلیونها آدم رو نجات میده، ولی بازم تو خیلی از کشورای کمدرآمد و متوسط، هر سال یه عالمه بچه به خاطر بیماریهایی که با واکسن قابل پیشگیری هستن، جونشونو از دست میدن. یعنی واقعاً جای کار داره! حالا یه سوال مهم اینه که چه جوری میشه پیشبینی کرد که چه بچههایی ممکنه واکسنهاشون رو به موقع نزده باشن یا اصلاً سراغش نرن؟ این کار نیاز داره که بتونیم اطلاعات مختلف (مثل شرایط خانوادگی، محیط اطراف، وضعیت جامعه و …) رو به شکلی وارد مدل کنیم که هوش مصنوعی یا مدلهای آماری بتونن روشون تحلیل انجام بدن.
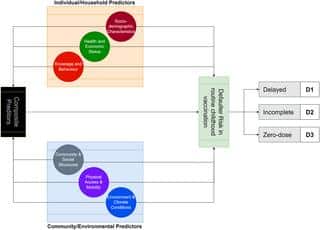
توی این مقاله که یه مرور کلی رو تحقیقات چند سال اخیر داره، اومدن گشتن ببینن دانشمندها چیا رو به عنوان ویژگی وارد مدل کردن تا ریسک واکسن نزدن بچهها رو تخمین بزنن. مثلاً ویژگی یعنی همون چیزایی که به مدل میدیم تا از روی اون ها پیشبینی کنه، مثل «وضعیت تحصیلات مادر»، «شغل مادر»، «وضعیت اقتصادی خانواده» یا حتی «جامعهای که توش زندگی میکنن».
کل جستوجو بین سالهای ۲۰۱۸ تا ژانویه ۲۰۲۵ انجام شده و تقریباً همه این مقالهها از آفریقا و کشورهای با درآمد پایین و متوسط بودن. دیتابیسهایی مثل PubMed، گوگل اسکالر (Google Scholar: موتور جستوجوی مقالات علمی)، ACM Digital Library و حتی منابع داخل خود مقالهها سرچ شده تا تحقیقی جا نمونه! از بین ۴,۱۷۴ تا مقالهای که جمع کردن، فقط ۵۵ تاش واقعاً به کار میومده که بعد از بررسی دقیقتر، ۴۱ تای دیگه هم حذف شدن و آخرش با جمع کردن ۴ تا دیگه از منابع دست دوم، یه مجموعه جمع و جور ولی حسابی مفید جمع کردن.
یه چیز جالب که بهش رسیدن اینه که تقریباً تو همه مودلها «تحصیلات مادر» و «استفاده مادر از خدمات سلامت» نقش پررنگی داشته. تازه، ویژگیهای جدیدی هم کشف کردن، مثل نرخ فقر تو جامعه یا اینکه چند درصد مادرها بیکارن. یعنی نشون میده محیط و ساختار اجتماع هم کلی تاثیر میذارن.
یه قسمت مهم کار، اینه که دادهها رو باید به یه فرم قابل فهم برای مدلهای هوش مصنوعی دربیاری. مثلاً دادههای دستهای (Categorical Data یعنی متغیرهایی که چندتا گزینه دارن مثل «زن یا مرد»، «بیکار یا شاغل») معمولاً به صورت «باینری» وارد میشن؛ یعنی با ۰ و ۱ نشون میدن. مثلاً اگه مادر شاغل باشه میشه ۱، اگر بیکار باشه میشه ۰. یا تو جاهایی که یه ویژگی مقادیر زیادی داره (مثلاً وضعیت اقتصادی که همش سطوح مختلف داره)، از روشی به اسم Principal Component Analysis (تحلیل مؤلفههای اصلی، یه تکنیک ریاضی برای خلاصهسازی دادههای پیچیده) استفاده میشه تا داده رو خلاصه و قابل استفاده کنن.
در کل، تفاوت زیادی تو نحوه تبدیل و ساخت ویژگیها تو این مقالات نبوده؛ یعنی تقریباً همه با هم مشابه کار کردن. ولی اینم گفتن که اگه قراره مدلهای هوش مصنوعی قویتری درست کنیم، باید از مدلهای جدیدتر کدگذاری داده استفاده کنیم. مثلاً به جای فقط باینری کردن دادهها میشه از «کدنویسی فرکانسی» (Frequency Encoding یعنی بر اساس تعداد رخداد هر دسته، یه عدد بهش اختصاص بدیم) هم استفاده بشه تا برای ویژگیهایی که چندتا دسته دارن، وزنهای مختلف بذاریم و مدل دقیقتر بشه.
کلاً این مقاله جمعبندی خوبی از اینه که دانشمندان تو زمینه پیشبینی کودکان واکسینهنشده چه ویژگیهایی رو انتخاب کردن و چه جوری دادهها رو مهندسی و کدگذاری کردن. همین میتونه یه راهنمای خوب باشه برای هر کسی که میخواد روشهای بهتر و دقیقتری برای پیشبینی ریسک جا موندن واکسن بچهها با هوش مصنوعی یا تحلیل آماری بسازه.
منبع: +



















