
Clio ابزاری نوآورانه است که با ناشناسسازی و دستهبندی مکالمات کاربران، شناخت عمیقتری از نحوهی استفاده از سیستمهای هوش مصنوعی مانند Claude فراهم میکند. این ابزار با رعایت استانداردهای بالای حریم خصوصی، نهتنها امنیت را ارتقا میدهد، بلکه اعتماد کاربران را نیز جلب میکند و کاربردهای واقعی این فناوری را شفافتر میسازد.
کاوش Clio: گامی به سوی هوش مصنوعی ایمنتر و هوشمندتر
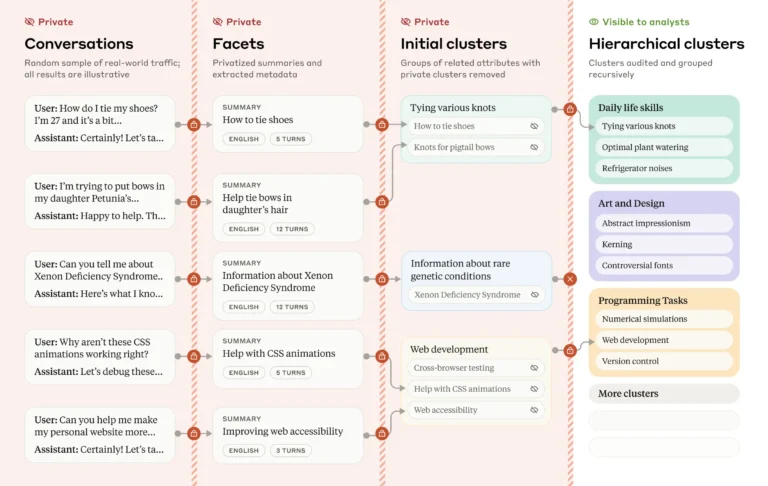
امروزه، سیستمهای هوش مصنوعی بیشتر و بیشتر در زندگی روزمرهی ما جای میگیرند. به همین دلیل، فهمیدن نحوهی استفادهی مردم از این سیستمها بسیار مهم است. اما یک چالش بزرگ وجود دارد: چگونه میتوانیم این اطلاعات را بدون به خطر انداختن حریم خصوصی کاربران بهدست آوریم؟ مدلهای Claude شرکت آنتروپیک این اصل را کاملاً رعایت میکنند و بهطور پیشفرض از مکالمات کاربران برای آموزش استفاده نمیکنند. Clio سیستمی منحصربهفرد است که برای حل همین چالش طراحی شده. Clio تحلیلهای خودکار و محرمانهای از کاربرد هوش مصنوعی در دنیای واقعی ارائه میدهد و اطلاعات ارزشمندی در اختیار ما قرار میدهد، بیآنکه به دادههای حساس کاربران دستبرد بزند.
اهمیت Clio
مدلهای زبان بزرگ (LLM) مانند Claude ابزارهایی بسیار انعطافپذیر با کاربردهای فراوان هستند. اما بهخاطر همین قابلیتهای زیاد، پیشبینی تمام کاربردهای محتمل – یا سوءاستفادههای ممکن – دشوار است. آزمایشهای قبل از راهاندازی و سیستمهای اعتماد و ایمنی به کاهش خطرات کمک میکنند، اما نظارت بر کاربرد واقعی این سیستمها چالشهای جدی بههمراه دارد.
Clio این خلاء را پر میکند. Clio به ما اجازه میدهد الگوهای تعامل کاربران را از پایین به بالا کشف کنیم. مثل Google Trends اما برای کاربرد هوش مصنوعی. این نهتنها به بهبود اقدامات امنیتی کمک میکند، بلکه نحوهی استفادهی کاربران از مدلهای زبان در زندگی روزمره را نیز روشن میسازد.
نحوهی کار Clio
Clio از یک فرآیند چند مرحلهای استفاده میکند که کاملاً توسط Claude پشتیبانی میشود تا حریم خصوصی و کارایی آن تضمین شود:
- استخراج ویژگیها: هر مکالمه از نظر ویژگیهایی مانند موضوع، تعداد پیامهای ردوبدل شده، و زبان مورد استفاده بررسی میشود.
- گروهبندی معنایی: مکالماتی که موضوعات مشابهی دارند، بهطور خودکار در گروههایی قرار میگیرند.
- شرح گروه: به هر گروه یک خلاصهی توصیفی داده میشود که موضوعات مشترک را بیآنکه به جزئیات خصوصی اشاره کند، بیان میکند.
- ساخت سلسله مراتب: گروهها در یک ساختار سلسله مراتبی سازماندهی میشوند تا تحلیلگران بتوانند الگوها را در ابعاد مختلف، مانند زبان یا موضوع، بهراحتی بررسی کنند.
طراحی Clio شامل چندین لایهی امنیتی برای حفظ حریم خصوصی است:
- دادهها ناشناس و تجمیع میشوند.
- موضوعات کمکاربرد برای به حداقل رساندن خطر شناسایی افراد حذف میشوند.
- Claude خلاصههای هر گروه را بررسی میکند تا مطمئن شود هیچ اطلاعات خصوصی قبل از ارائه به تحلیلگران در آنها وجود ندارد.
این اقدامات بهدقت آزمایش شدهاند و در مقالهی تحقیقاتی آنتروپیک که همزمان با معرفی Clio منتشر شده، بهطور کامل شرح داده شدهاند.
بینشهایی از Clio
Clio در حال حاضر اطلاعات ارزشمندی در مورد نحوهی تعامل کاربران با Claude.ai، هم در نسخهی رایگان و هم نسخهی حرفهای، ارائه داده است:
- کمک به کدنویسی: بیش از ۱۰٪ مکالمات مربوط به کدنویسی بودهاند، از جمله رفع اشکال و توضیح مفاهیم فنی.
- آموزش: آموزش و یادگیری بیش از ۷٪ مکالمات را به خود اختصاص داده است.
- استراتژی کسبوکار: تقریباً ۶٪ مکالمات شامل کارهای حرفهای مانند نوشتن نامههای اداری یا تجزیهوتحلیل دادههای کسبوکار بودهاند.
علاوه بر این موارد اصلی، Clio هزاران گروه کوچکتر را کشف کرده که روشهای متنوع استفاده از Claude را نشان میدهند – از تعبیر خواب و آمادگی در برابر بلایای طبیعی گرفته تا بازی و حتی کارهای خاصی مانند شمارش حروف در کلمات.
الگوهای خاص زبان
Clio همچنین تفاوتهای کاربرد را در زبانهای مختلف نشان داده است که بیانگر تفاوتهای فرهنگی و نیازهای منحصر به فرد هستند. برای مثال:
- مکالمات اسپانیایی بیشتر به موضوعات مربوط به رویدادهای اجتماعی میپرداختند.
- کاربران چینی اغلب بر روی برنامهریزی مالی یا طب سنتی تمرکز میکردند.
- کاربران ژاپنی علاقهی خود را به موضوعاتی مانند آداب و رسوم و شعر نشان میدادند.
تقویت سیستمهای ایمنی
Clio فقط برای فهم کاربرد نیست – بلکه ابزاری قدرتمند برای بهبود سیستمهای ایمنی در آنتروپیک است:
- اجرای اعتماد و ایمنی: Clio به شناسایی گروههایی کمک میکند که ممکن است نشاندهندهی نقض قوانین استفاده، مانند تولید محتوای گمراهکننده یا تشویق رفتارهای مضر، باشند. با کنترلهای دسترسی سختگیرانه، فقط کارکنان مجاز میتوانند فعالیتهای مشکوک را برای اقدامات لازم بررسی کنند.
- تشخیص سوءاستفادهی هماهنگ: در یک مورد، Clio شبکهای از حسابها را شناسایی کرد که از دستورات مشابه برای تولید هرزنامه برای بهینهسازی موتور جستجو استفاده میکردند – فعالیتی که مخالف قوانین آنتروپیک بود و منجر به حذف حسابها شد.
- نظارت بر موارد پرخطر: قبل از رویدادهایی مانند انتخابات عمومی ۲۰۲۴ ایالات متحده، از Clio برای نظارت بر مکالمات سیاسی و مربوط به رأیگیری استفاده شد که به جلوگیری از خطرات یا سوءاستفاده کمک کرد.
- کاهش موارد مثبت/منفی کاذب: Clio مکمل طبقهبندیکنندههای موجود است و مواردی را شناسایی میکند که ممکن است از دست بروند (منفی کاذب) یا بهاشتباه علامتگذاری شوند (مثبت کاذب). برای مثال، محتوای مضر را در مکالمات ترجمه شده که سایر سیستمها آن را نادیده گرفته بودند، شناسایی کرد و همزمان علامتگذاریهای غیرضروری را در فعالیتهای بیخطر مانند درخواستهای کاریابی یا بحثهای بازی کاهش داد.
ملاحظات اخلاقی
توسعهی Clio مستلزم پرداختن به چندین چالش اخلاقی بود تا تضمین شود که با تعهد آنتروپیک به توسعهی مسئولانهی هوش مصنوعی سازگار است:
- مثبتهای کاذب: برای جلوگیری از مجازات محتوای بیخطر، از خروجیهای Clio برای اقدامات اجرایی خودکار استفاده نمیشود. در عوض، عملکرد آن با دقت در مجموعه دادههای مختلف بررسی میشود.
- سوءاستفادهی احتمالی: کنترلهای دسترسی سختگیرانه، به حداقل رساندن دادهها و سیاستهای نگهداری، خطر نظارت نامناسب یا سوءاستفاده از Clio را کاهش میدهند.
- حریم خصوصی کاربر: ممیزیها و بهروزرسانیهای منظم تضمین میکنند که Clio استانداردهای بالای حریم خصوصی خود را حفظ میکند. طراحی آن شفافیت را در اولویت قرار میدهد تا اعتماد کاربر را جلب کند و مزایای آن را برای حاکمیت هوش مصنوعی نشان دهد.
آیندهی هوش مصنوعی با حفظ حریم خصوصی
Clio گامی مهم در متعادل کردن دو مسئولیت ارائهدهندگان هوش مصنوعی است: تضمین امنیت و همزمان حفظ حریم خصوصی کاربر. Clio با فراهم کردن بینشهای مبتنی بر داده، بدون به خطر انداختن اطلاعات حساس، استاندارد جدیدی را برای توسعهی مسئولانهی هوش مصنوعی تعریف میکند.
در حالی که آنتروپیک به بهبود Clio ادامه میدهد، امیدوار است دیگران را در جامعهی هوش مصنوعی به اتخاذ رویکردهای مشابه تشویق کند. با تقویت شفافیت و همکاری، ابزارهایی مانند Clio میتوانند به ایجاد یک اکوسیستم هوش مصنوعی ایمنتر و قابل اعتمادتر برای همه کمک کنند.
برای علاقهمندان به مشارکت در این تلاش، آنتروپیک در حال استخدام برای تیم تأثیرات اجتماعی خود است – و فرصتی را برای کار بر روی پروژههای پیشرفتهای مانند Clio که آیندهی حاکمیت و امنیت هوش مصنوعی را شکل میدهند، ارائه میدهد.
اگر به خواندن کامل این مطلب علاقهمندید، روی لینک مقابل کلیک کنید: anthropic.com

















