
خب بچهها، میخوام یه بحث جذاب و دوستانه درباره مدلهای زبانی بزرگ (LLMs) داشته باشیم و اینکه این مدلهای هوش مصنوعی اصلاً تو حوزه آنکولوژی یا همون سرطانشناسی چه جوری دارن استفاده میشن. LLM یعنی مدلهایی که میتونن متن رو تحلیل کنن یا حتی خودشون نوشته تولید کنن (مثلاً ChatGPT یا Bard یا همین مدلهای جدید فارسی). یعنی واقعاً چیزای عجیب غریبی میتونن انجام بدن و کلی برای پزشکها و محققها جذابه.
یکی از چیزایی که تو این تحقیق اومده اینه که اکثر استفادههای LLM تو سرطانشناسی، هنوز تازهکار و نوپا هست و برخلاف جاهای دیگه مثل موضوعات کلیتر، کمتر مدل مخصوص سرطان داریم. اگه برات سوال شد که “Generative pre-trained transformer (GPT)” یعنی چی، بدون این مدلها توسط AI قبلش کلی تمرین کردن تا بتونن متن تولید کنن.
محققین برای این بررسی یه عالمه مقاله علمی رو از دیتابیسهایی مثل ACM و Medline و Scopus و غیره تا دی ماه ۱۴۰۲ (ژانویه ۲۰۲۴) زیر و رو کردن و از بین ۱۴،۸۶۳ تا مقاله، آخرسر ۶۰ تا رو انتخاب کردن! واقعاً باید یه کلاه از سر برداشته بشه برای این حجم دقت و جستجو.
حالا این ۶۰ مقاله رو که بررسی کردن، دیدن این مدلها تو موضوعات خیلی متنوع سرطانشناسی بررسی شدن. بیشترین کاربردها مربوط به تشخیص (مثلاً کمک به پیدا کردن نوع سرطان) و درمان بوده. یعنی وقتی کسی سر و کارش با مرحلههای مختلف سرطان هست، میرن سراغ این مدلها که ایده یا کمک بگیرن.
کلاً دادههایی که برای آموزش و تست این مدلها استفاده شده، خیلی جورواجور بوده: از پروندههای واقعی بیماران گرفته تا دادههای ساختگی (یعنی مصنوعی که خودشون با روشهای خاص ساختن)، مقالات علمی و حتی مطالبی که تو شبکههای اجتماعی نوشته شده! مثلاً یکی از کارهای جالبشون اینه که قبل از اینکه اطلاعات رو بدن به مدل، باید سوالات یا متون رو جوری طراحی کنن که مدل بهینه جواب بده؛ این رو بهش میگن “Prompt- Engineering” یعنی ساختن و تنظیم مناسب سوال برای مدل.
جالب اینجاست که این مدلهای سرطانمحور فقط مخصوص پزشکها و محققها نیستن، بلکه مخاطبهایی مثل دانشجوهای پزشکی و حتی خود بیماران هم بودن. این یعنی مدلها دارن وارد زندگی روزمره و حتی آموزش میشن.
تو حدود ۱۷ درصد از مقالات، خودشون مدل جدید ساختن یا مدلهای قبلی رو برای سرطان شخصیسازی کردن. این کار رو با یه روشی به اسم “پیشآموزش (Pre-training)” و “فاینتیونینگ (Fine-tuning)” انجام میدن، یعنی مدل رو با دادههای مخصوص سرطان دوباره تمرین میدن تا بهتر جواب بده.
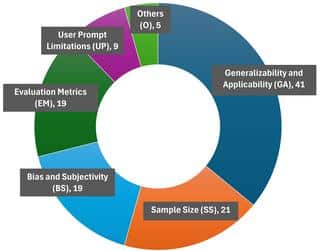
اما یادت نره، همه جا عالی و بینقص نیست! تو این مقالهها چندتا مشکل مشترک دارن هی تکرار میکنن. مثلاً یکی از بزرگترین دغدغهها اینه که این مدلها رو تو کشورهای مختلف یا برای جمعیتهای متنوع امتحان نکردن، پس هنوز نمیدونیم جوابشون چقدر همگانیه (به این میگن “محدودیت در تعمیم پذیری”). یا اینکه تعداد نمونههایی که مدل باهاش تمرین داده شده کمه، یا حتی بعضی وقتا یهکم اطلاعات مغرضانه یا سوگیرانه بوده. تازه یه مشکلی هم اینه که روشهای ارزیابی این مدلها بعضی وقتا استاندارد نیست، یعنی هرکس با متد خاص خودش تست کرده و این کار رو سختتر میکنه.
در کل، این مقاله نتیجه گرفته که کاربرد مدلهای زبانی بزرگ تو سرطانشناسی واقعاً گسترده و هیجانانگیزه، ولی هنوز تا رسیدن به یه ابزار قابل اعتماد و کاربردی راه دارن. مخصوصاً نیاز به مدلهایی هست که فقط برای سرطان ساخته بشن و بتونن تو آموزش و درمانهای مختلف استفاده شن. خلاصه، آینده متعلق به مدلهای هوش مصنوعی تو پزشکیه، ولی فعلاً باید کلی کار و تحقیق انجام شه تا قویتر و کم نقصتر شن. پس اگه قراره دکتر بشی یا تو حوزه درمان کار کنی، حتماً حواست به رشد و ارتقای این مدلها باشه!
منبع: +
















