
تا حالا اسم DIANA به گوشت خورده؟ این یه ابزار هوشمنده که مخصوصاً برای افرادی که توی هند و جنوب آسیا به دیابت نوع ۲ مبتلا هستن طراحی شده و واقعاً کار راهاندازه! بذار اول یه کم راجع به دستهبندیهای جدید دیابت نوع ۲ برات توضیح بدم.
چند وقت پیش، پژوهشگرها فهمیدن که دیابت نوع ۲ فقط یه بیماری ساده نیست و آدمها با شرایط مختلف بهش مبتلا میشن. واسه همین چهار تا زیرگروه اصلی (که بهشون میگن endotype – یعنی نوع خاص بیماری با ویژگیهای متفاوت) پیدا کردن:
- SIDD: Severe Insulin Deficient Diabetes – یعنی افرادی که بدنشون به شدت کمبود انسولین داره.
- CIRDD: Combined Insulin Resistant and Deficient Diabetes – یعنی ترکیبی؛ هم بدن خوب انسولین نمیسازه، هم نسبت بهش مقاومه.
- IROD: Insulin Resistance and Obese Diabetes – یعنی بدنشون به انسولین مقاومه و معمولاً اضافهوزن هم دارن.
- MARD: Mild Age-related Diabetes – مدل خفیف و معمولاً تو سنین بالاتر اتفاق میافته.
حالا بیایم سر اصل مطلب: دایانا چی کار میکنه؟
ابزار DIANA با کمک هوش مصنوعی (که مثلاً ماشین لرنینگ یا یادگیری ماشینی یه شاخه ازشه و باعث میشه کامپیوترها خودشون یاد بگیرن) به دکترها کمک میکنه بفهمن که یه فرد مبتلا به دیابت نوع ۲ تو کدوم زیرگروه قرار میگیره و بیشتر احتمال داره به عوارضی مثل بیماری کلیوی (nephropathy – یعنی آسیب به کلیهها به خاطر دیابت) یا رتینوپاتی (retinopathy – یعنی آسیب به چشم و شبکیه به خاطر دیابت) دچار بشه یا نه.
روش کار چطوریه؟
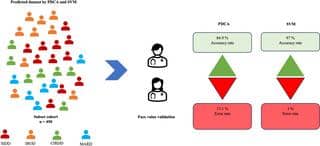
دایانا از یه مدل ماشینی به اسم Support Vector Machine یا همون SVM (یه روش هوشمند برای دستهبندی دادهها تو یادگیری ماشینی) استفاده میکنه. مدلش رو با اطلاعات واقعی از مبتلایان دیابت تو هند آموزش دادن (با روش کروس-ولیدیشن که یعنی دادهها رو چند بار تقسیم و جابجا میکنن تا مطمئن بشن الگوریتم درست یاد میگیره).
چه چیزهایی رو لازم داره؟ یه سری داده ساده مثل سن شروع دیابت، BMI (نمایه توده بدنی یعنی قد و وزن نسبت به هم)، سایز دور کمر، HbA1c (که قند خون طی سه ماهه اخیر رو نشون میده)، تریگلیسرید خون، HDL-کلسترول (کلسترول خوب) و حتی اطلاعات C-peptide (که نشون میده پانکراس چقدر انسولین تولید میکنه) – البته این آخریا اختیاری هستن.
برای اینکه چطوری این مدل تصمیم میگیره و رفتار مدل شفاف باشه، از دو تکنیک جذاب استفاده کردن: LIME (Local Interpretable Model-Agnostic Explanations) و SHAP (SHapley Additive exPlanations). اینا کمک میکنن دکترها بفهمن دقیقاً چه چیزی باعث شده مدل چنین تصمیمی بگیره. انگار که مدل داره منطق خودش رو رو برات توضیح میده!
در مورد پیشبینی ریسک عوارض مثل آسیب کلیوی و چشمی هم، یه الگوریتم دیگه به اسم Random Forest استفاده کردن (یه جور مدل یادگیری ماشینی که با کلی درخت تصمیمگیری، پیشبینی انجام میده).
نتایج چی شدن؟
واقعا مدلشون ترکونده! مثلاً دقت مدل SVM نسبت به روشهای سادهتر که فقط بر اساس چندتا عدد ثابت تصمیم میگرفتن، خیلی بالاتر بوده:
- دقت: ۹۸٪ در مقابل ۶۳.۶٪
- ویژگی (Specificity): ۹۹.۸٪ در مقابل ۸۸٪
- حساسیت (Sensitivity): ۹۸.۵٪ در مقابل ۶۵.۱٪
- صحت (Precision): ۹۸.۷٪ در مقابل ۶۳.۴٪
حتی وقتی چندتا دکتر اومدن بررسی کنن که مدل واقعاً داره درست کار میکنه یا نه، باز هم نتایجش فوقالعاده بود. دقت: ۹۷٪ در مقابل ۸۵٪ و صحت: ۹۸.۹٪ در برابر ۶۶.۹٪ روش قدیمی.
در پیشبینی بیماری کلیوی و چشمی هم، مدل Random Forest به ترتیب دقت ۸۹.۶٪ و ۷۸.۴٪ داشته (که تو کارهای پزشکی خیلی عددهای خوبیان!).
جمعبندی چی میشه؟
ابزار DIANA، یه دستیار هوشمند جدیده که واسه دستهبندی دقیق بیماران، پیشبینی ریسک عوارض و مدیریت بهینه دیابت نوع ۲ طراحی شده. دکترها راحت میتونن ازش استفاده کنن و تصمیمهای دقیقتر و هوشمندانهتری بگیرن. همه اینها با کمک هوش مصنوعی انجام میشه تا آینده کنترل دیابت خیلی دقیقتر و شخصیتر باشه!
پس اگر خودت یا کسی رو میشناسی که با دیابت نوع ۲ کلنجار میره، بهش بگو که دیگه ابزارهای هوشمند قراره کمکشون کنن یه سر و سامون حسابی به بیماری بدن و از عوارض جدی جلوگیری کنن!
منبع: +



















