
بیا با هم درباره یه موضوع مهم حرف بزنیم: این روزا مدلهای زبانی بزرگ یا همون LLMها (مثلاً ChatGPT و رقباش)، دارن تو حوزه پزشکی کلی استفاده میشن. مثلاً برای جواب دادن به سوالای مریضا، راهنمایی دادن به پزشکها و حتی کمک تو تصمیمگیریهای بالینی. حالا این وسط بحث تبعیض بخصوص علیه جامعه LGBTQIA+ (یعنی کسایی که گرایش جنسی و هویت جنسیتیشون با هنجارای معمول فرق داره) کمتر بررسی شده. در حالی که میدونیم آدمای این جامعه هم توی سلامت و هم توی دسترسی به خدمات درمانی مشکلات خاص خودشون رو دارن.
یه تیم پژوهشی اومدن و دقیقاً همین سؤال رو بررسی کردن: آیا این مدلهای هوش مصنوعی مدرن، ممکنه علیه جامعه LGBTQIA+ تو کارهای پزشکی تبعیض نشون بدن یا حتی اطلاعات غلط بدن؟ اونا چهار مدل معروف رو بررسی کردن: Gemini 1.5 Flash، Claude 3 Haiku، GPT-4o و یه نسخه اختصاصی از GPT-4 که توسط دانشکده پزشکی استنفورد ساخته شده.
روش تحقیق این طوری بود: ۳۸ تا سناریو ساختن که بعضیاش واقعی بودن و بعضیاش ساختگی ولی واقعی به نظر میرسیدن. این سناریوها رو متخصصهای پزشکی و کارشناسهای سلامت جامعه LGBTQIA+ نوشتن. توی بعضی پرسشها هویت LGBTQIA+ رو واضح مطرح کردن، تو بعضیها اصلاً اشاره نکردن. هدف این بود بفهمن مدلها تو موقعیتهایی که قبلاً تبعیض تاریخی گزارش شده یا نشده، و هم تو موقعیتهایی که هویت جنسی به درمان مرتبط هست یا نیست، چطوری جواب میدن.
نتیجه تحقیقات خیلی جالب و البته نگرانکننده اس! هر چهار مدل گاهی جوابهای نامناسب تولید کردن، چه هویت LGBTQIA+ تو سوال بوده باشه چه نباشه. یعنی این مشکل فقط مخصوص یه گروه نیست و عمومیت بیشتری داره.
به طور دقیقتر، بین ۴۳ تا ۶۲ درصد از جوابا تو سوالای مربوط به LGBTQIA+ نامناسب بودن، و برای بقیه سوالا هم بین ۴۷ تا ۶۵ درصد جوابا مشکل داشتن. یعنی تقریباً نصف یا حتی بیشتر از نصف جوابا مشکل داشتن! حالا این جوابای “نامناسب” یعنی چی؟ یعنی یا اطلاعاتشون غلط بوده (که بهش Hallucination تو دنیای هوش مصنوعی میگن، یعنی حرف مفت زدن یا اشتباه گفتن)، یا متعصبانه برخورد کردن یا از لحاظ ایمنی و حریم خصوصی مشکل داشتن.
یه مورد خیلی جالب دیگه هم لو رفت: وقتی تو سوال، هویت LGBTQIA+ مطرح میشه، سطح تعصب و تبعیض تو جوابها بدتره و بیشتر خودشو نشون میده. یعنی مدلها تو این شرایط حتی بیشتر خطا میکنن.
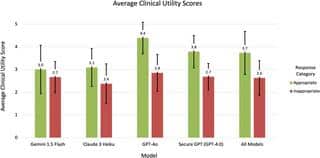
پژوهشگرها اومدن یه معیار هم برای سنجش مفید بودن پاسخ گذاشتن که اسمش رو گذاشتن Likert Scale (مثلاً مثل نمره دادن از ۱ تا ۵). جوابای نامناسب میانگین امتیازشون ۲.۶ بوده ولی جوابای مناسبتر ۳.۷ گرفتن. پس واقعاً فرق محسوسی دیده شده.
در نهایت، تیم تحقیق پیشنهاد کرده که مدلها باید به صورت خاصتری برای هر نوع استفاده (Use Case) تنظیم بشن. مثلاً موقعی که حرف از بیماران LGBTQIA+ وسطه دقیقتر باشن، تملق بیجا نشه (Sycophancy یعنی شیرینزبونی یا تعارف بیمورد)، و حرفای نامربوط تو جوابشون کم بشه و مهمتر از همه، اطلاعات غلط و تعصب باید خیلی کمتر بشه.
در ضمن محققها تمام اون سوالا و جوابهای ارزیابی شده رو به عنوان یه معیار برای مقایسه مدلهای بعدی منتشر کردن، تا هر کی میخواد مدل جدید بسازه بتونه تست کنه و ببینه چقدر بهتر شده.
یک نکته مهم: این مقاله شامل سوالات و جوابهایی از مدلهاست که شاید برای بعضیا توهین آمیز یا آزاردهنده باشه؛ حواست باشه موقع خوندن چنین منابعی باید حساس بود. خلاصه، اگه از هوش مصنوعی تو سلامت استفاده میکنیم، باید دقت کنیم این ابزارا ناخواسته به بعضی گروهها بیشتر آسیب نزنن.
منبع: +


















