
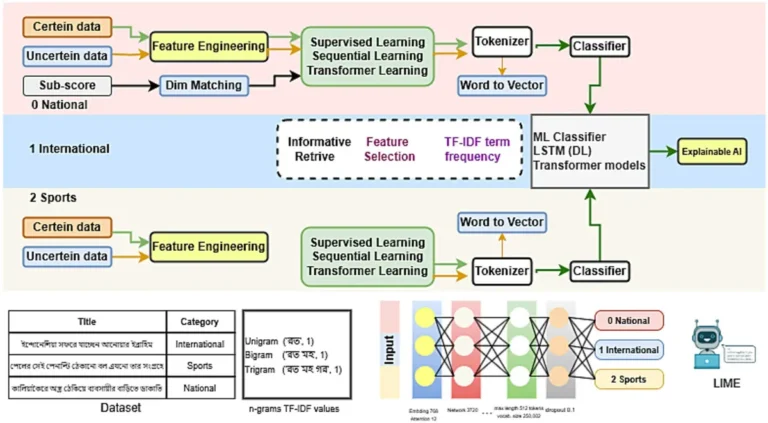
خب ببین، موضوع اصلی این تحقیق اون دسته از متنهای پراکنده به زبان بنگالیه که باید دستهبندی بشن. حالا چرا این اهمیت داره؟ چون زبان بنگالی رو حسابی میشه به عنوان یه زبان کممنبع (یعنی زبانی که داده و مدلهای آمادهی زیادی براش وجود نداره) در نظر گرفت. این خودش یه چالش حسابی تو پردازش زبان طبیعی یا همون NLP میاره. خب، NLP همون حوزهایه که دنبال اینه بفهمه کامپیوترها چجوری میتونن زبان ما آدما رو بفهمن و پردازش کنن!
توی این کار، اولش با چندتا مدل یادگیری ماشینِ سنتی (یعنی همون ML، مدلهایی که داده رو میگیرن و سعی میکنن از قبل بتدریج قاعده پیدا کنن) شروع کردن تا یه پایه برای مقایسه داشته باشن. بعدش رفتن سمت یادگیری عمیق، اینجا یه مدلی رو امتحان کردن به اسم LSTM، که خلاصهش اینه: مخصوص کارهای ترتیبیه، مثل متن و صدا. راحتتر بگم، LSTM یه نوع شبکه عصبیه که میتونه اطلاعات رو واسه مدت بیشتری تو ذهنش نگه داره، پس برای متنهای طولانی گزینهی خوبیه.
اما قصه اینجا تموم نمیشه! تیم تحقیق رفت سراغ مدلهای ترنسفورمر. ترنسفورمرها (transformer) الان تو دنیای یادگیری ماشین حسابی معروف شدن چون وقتی پای زبان به میون میاد، کم نمیارن! این مدلها واسه کارایی مثل ترجمه، دستهبندی متن، یا حتی تولید متن عالی عمل میکنن.
برای این تحقیق، یه سری اخبار جدید بنگالی رو از اینترنت جمعآوری کردن (خودش کلی زحمت داره چون دادههای بنگالی پر از نویز و شلوغیه)، بعد کلی پیشپردازش و مهندسی ویژگی (feature engineering یعنی انتخاب اون بخشهایی از داده که میتونن به مدل زیاد کمک کنن) روش انجام دادن تا دیتاست رو حسابی تمیز کنن.
وقتی مدلها رو امتحان کردن، چیزی که از همه دقیقتر عمل کرد یه مدل ترنسفورمیری به اسم XLM-RoBERTa Base بود. این مدل تونست به دقت ۰.۹۱ برسه – عدد خیلی خوبیه مخصوصاً برای زبانی که خیلی داده براش نیست!
ولی فقط دقت بالا ملاک نیست؛ مسئله توضیحپذیری یا همون Explainability هم مطرحه. این یعنی مدل هوش مصنوعی فقط نباید جواب بده، باید بتونیم بفهمیم چرا این جواب رو داده، و بهش اعتماد پیدا کنیم. اینجا از یه ابزار به نام LIME استفاده کردن. LIME مخفف Local Interpretable Model-agnostic Explanationsه، که سادهتر بگم یعنی یه جوری خروجی مدل رو توضیح میده که حتی اگه مدل برات غریبه باشه، باز بفهمی چرا این پیشبینی شده!
LIME کمک کرد بفهمن کدوم ویژگیها یا کدوم کلمهها توی عنوان خبرها تاثیر بیشتری داشتن تا اون خبرها درست دستهبندی بشن. اینجوری اطمینان حاصل شده که نتایج مدل فقط تصادفی نبوده و واقعاً درست یاد گرفته.
در نتیجه، این تحقیق نشون داد که مدلهای یادگیری عمیق مخصوصاً ترنسفورمرها، برای دستهبندی متن به زبان بنگالی خیلی قوی عمل میکنن. از همه مهمتر، توضیحپذیری باعث میشه مدل شفافتر باشه و آدمها بیشتر به نتیجههاش اعتماد کنن. خلاصه اگر یه روز بخوای مدل هوش مصنوعی روی متنهای بنگالی پیاده کنی، ترنسفورمر و توضیحپذیری رو فراموش نکن!
منبع: +

















