
خب رفقا، امروز میخوام یه موضوع خیلی جالب و جدید رو باهاتون درمیون بذارم: استفاده از مدلهای زبانی بزرگ مثل GPT-4 و GPT-3.5-turbo برای نوشتن خلاصه ویزیتهایی که توی اورژانس بیمارستان انجام میشه! یعنی یه جورایی میخوان به کمک هوش مصنوعی کارهای نوشتاری پزشکها رو راحتتر کنن، مخصوصاً وقتی بخش اورژانسه و همه سرشون شلوغه.
حالا اول یه توضیح کوچیک: مدل زبان بزرگ یا Large Language Model (LLM) همون هوش مصنوعی مثل ChatGPT هست، که میتونه متن بنویسه، خلاصه درست کنه یا حتی سوالها رو جواب بده. خلاصه وقتی از LLM حرف میزنیم، یعنی ابزارای هوش مصنوعی که با حجم عظیم اطلاعات آموزش دیدن تا بتونن مثل آدم باهات حرف بزنن یا برات مطلب درست کنن.
توی تحقیق جدیدی که چندتا محقق از دانشگاه کالیفرنیا سن فرانسیسکو انجام دادن، اومدن دقیقا بررسی کردن ببینن اگه خلاصه ویزیت اورژانس (ED Encounter Summary) رو بسپارن به GPT-4 و GPT-3.5-turbo، چی درمیاد؟ یعنی همون خلاصهای که توش دلیل مراجعه بیمار، معاینات، سابقه بیماری و برنامه درمانی نوشته میشه.
اینا اومدن 100 تا ویزیت تصادفی از بازه سالهای 2012 تا 2023 رو انتخاب کردن (از پرونده بیماران بزرگسال در اورژانس سن فرانسیسکو)، بعد خلاصه این ویزیتها رو سپردن دست دو مدل هوش مصنوعی معروف و بعد با دقت بررسی کردن ببینن عملکردشون چطور بوده.
تو این تحلیل، سه تا نکته مهم رو چک کردن:
1. اطلاعات نادرست یا Inaccuracy (یعنی دادههایی که اشتباه وسط متن اضافه شدن)
2. هذیان یا Hallucination (یعنی هوش مصنوعی یه چیزایی رو از خودش درمیاره که تو داده واقعی وجود نداره – خلاصه قاطی میکنه!)
3. جاافتادگی اطلاعات مهم (یعنی نکات مهم پزشکی اصلاً تو خلاصه نوشته نشده)
خب بریم سراغ نتایج باحال مطالعه!
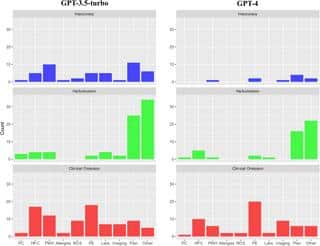
– 33٪ خلاصههایی که توسط GPT-4 نوشته شدن، کاملاً بدون هیچ خطایی بودن. این عدد برای GPT-3.5-turbo فقط 10٪ بوده. یعنی GPT-4 دست بالا رو داره!
– خلاصههای GPT-4 توی 90٪ مواقع اطلاعات درستی داشتن و فقط تو 10٪ خلاصهها اشتباه دیدن. ولی چشمبسته بهش اعتماد نکنین، چون در عوض 42٪ مواقع یه چیزایی از خودش درآورده (Hallucination کرده) و 47٪ وقتها هم اطلاعات مهم و پزشکی رو جا انداخته!
– بیشترین اشتباه (چه نادرستی، چه هذیان) معمولاً تو بخش برنامه درمانی یا همان Plan اتفاق افتاده. اگه خلاصه معاینه بیمار (Physical Examination) یا تاریخچه شکایت اصلی بیمار (History of Presenting Complaint) رو نگاه کنیم، میبینیم اکثر جاافتادگیها اینجان.
در کنار همه اینا، محققها اومدن ارزیابی کردن ببینن هر اشتباه یا خطا چقدر میتونه برای بیماران خطرناک باشه. میانگین نمره خطر (harmfulness) برای خطاها فقط 0.57 از 7 بوده! یعنی در کل این اشتباهات زیاد هم تهدید آمیز نیست. فقط توی سه مورد نمره خطر 4 یا بالاتر گرفته، که یعنی پتانسیل آسیب دائمی داشتن.
نتیجهگیری چیه؟ یه جورایی باید گفت LLMها مثل GPT-4 خیلی خوب از پس خلاصهنویسی برمیان و تو خیلی از موارد هم خلاصههای دقیقی مینویسن. با این حال، هنوز هم ممکنه حرف از خودشون در بیارن یا نکات مهم پزشکی رو جا بندازن. پس نباید بیگدار به آب زد و همه کار رو بسپریم به هوش مصنوعی!
در نهایت، این تحقیق نشون میده که اگه پزشکها بدونن کجا و از چه نظر ممکنه هوش مصنوعی سوتی بده، میتونن راحتتر و سریعتر خلاصههای تولیدشده رو بررسی کنن و جلوی آسیب جدی به بیمار رو بگیرن.
پس اگه دیدین از این به بعد تو اورژانس دکترتون زودتر خلاصه مینویسه، بدونین شاید هوش مصنوعی هم داره بهش کمک میکنه! ولی هنوزم باید یه چشم پزشک و کارشناس روش باشه تا مطمئن بشن همه چی درسته.
منبع: +










