
خب رفیق! بیاید یه داستان جالب براتون تعریف کنم درباره اینکه چطوری محققها خواستن با کمک هوش مصنوعی بفهمن کدوم آدمایی که تو برنامههای مدیریت دیابت شرکت میکنن، وسط راه برنامه رو ول میکنن و دیگه ادامه نمیدن! میدونی، ترک کردن برنامه (یا همون attrition توی دانشگاهیها!) یکی از بزرگترین چالشها تو برنامههای سلامت مثل همین دیابتگردونه!
تا حالا میدونستید حدود ۱۱.۶ درصد آمریکاییها دیابت دارن؟ مخصوصا توی ایالت South Carolina اوضاع جدیتر هم هست و کلی بزرگسال با این بیماری زندگی میکنن. جالبه که برنامههای آموزش و خودمدیریت دیابت، مثل HED یا همون Health Extension for Diabetes، نشون دادن حسابی به آدمها کمک میکنن، هم تو کاهش وزن خوبن و هم تو ارتقا اطلاعاتشون درباره دیابت و کنترل بهترش.
حالا چون تعداد دیابتیها داره هی بیشتر میشه، خیلی مهمه آدمهایی که به برنامهها میان، بمونن و وسطش رها نکنن. نکته اینجاست که خیلی وقتا ترک وسط برنامه اتفاق میافته و این یعنی احتمالا یک جای کار میلنگه! محققها خواستن از ماشین لرنینگ استفاده کنن. ماشین لرنینگ (machine learning) یعنی یه جور هوش مصنوعی که الگوها رو از داده میگیره و سعی میکنه پیشبینی کنه، یعنی به جای اینکه همه چی رو دستی حساب کنی، مدل بهت میگه چی محتمله.
tمحققا دادههای شرکتکنندههای برنامه HED رو جمع کردن. کلی عدد و رقم داشتن از شرکتکنندهها؛ از مشخصات جمعیتشناسی یعنی سن، نژاد، قد و تحصیلات گرفته تا بعضی فاکتورهای جالب مثل فاصله زمانی خونه تا نزدیکترین سوپرمارکت (آره، همینقدر خاص و خلاق بودن!) و امتیازهای کیفیت زندگی مثل SF-12 (یه نوع پرسشنامه استاندارد برای سنجیدن کیفیت زندگی افراد) و نمره DCI یا Distressed Communities Index (این هم یه شاخص برای سنجیدن چقدر جامعه از نظر اجتماعی-اقتصادی تو بحران هست).
اول آمارهای توصیفی و یه سری تست آماری (مثل Mann-Whitney U و کای-دو که فقط بدونید تست آماریان برای اینکه ببینن بین گروهها تفاوت معنادار هست یا نه) انجام دادن. بعد رفتن سراغ مدلهای ماشین لرنینگی مختلف تا ببینن میتونن اجاره بدن کدوم شرکتکنندهها زودتر برنامه رو ول میکنن یا نه.
مدلهایی که تست کردن چندتا بودن؛ ولی بهترین عملکرد رو مدل XGBoost (اینم یه مدل خیلی معروف و قوی تو کارهای داده مثل دستهبندی) با تکنیک downsampling داد. downsampling یعنی از دادههایی که خیلی زیاد بودن کمی حذف کردن تا مدل نتایجش غیرواقعی و شیرین نشه! با همه این کارها نهایتا مدل XGBoost بهترینش بود ولی بازم امتیازش خیلی بالا نبود: AUC برابر 0.64 (یه جور معیار سنجش قدرت پیشبینی مدل که معمولاً بالای 0.8 خوبه!) و F1 از 0.36 (F1 Score هم یه شاخصه که نشون میده مدل چقدر دقیق جواب میده؛ هر چی بالاتر، بهتر). خلاصه بخوایم روراست باشیم، پیشبینی خیلی قویای نتونستن بکنن چون عددها خیلی پایین بودن. به قولی مدلها هنوز راه زیادی دارن تا بشه با خیال راحت روشون حساب کرد.
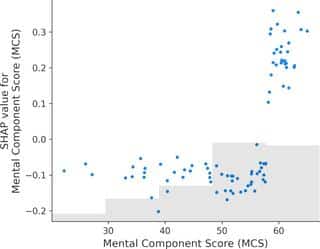
یه تکنیک مهم دیگه که استفاده کردن، SHAP بود؛ یعنی SHapley Additive exPlanations. این ابزار کمک میکنه بفهمی چرا یه مدل ماشین لرنینگ یه پیشبینی خاص رو میده، یعنی مدل رو قابل فهمتر میکنه (چون خیلی وقتا مدلهای هوش مصنوعی مثل جعبه سیاهن!).
جالبترین یافتهشون چی بود؟ اینکه یه سری فاکتور مثل کیفیت زندگی (SF-12)، شرایط نابسامان اجتماعی (DCI)، مشخصات فردی (سن، نژاد، قد، تحصیلات)، و حتی مدت زمان رسیدن به سوپرمارکت محل، همشون رو میزان ترک کردن برنامه اثر داشتن. اینا سرنخهای خوبی بودن تا بفهمیم چه کسایی بیشتر در خطر ول کردن برنامه هستن.
البته! خود محققها هم میگن فعلاً این مدلها خیلی قابل اعتماد نیستن واسه اینکه بخوایم رو یه نفر خاص پیشبینی کنیم آیا برنامه رو ادامه میده یا نه. بیشتر این مدلها فعلاً برای این خوبن که بفهمن عوامل موثر چیاس، نه اینکه «حتماً» پیشبینی کنن. نتیجه کلیشون اینه که پیشبینی رفتارهای سلامتی به این راحتیها نیست و کلی کار و تحقیق بیشتر نیازه تا مدلهای دقیقتر و کاربردیتر بسازیم. هدف نهایی هم اینه که بتونن با این مدلها به شکلی مردم رو بیشتر توی برنامه نگه دارن و کسی وسط راه کم نیاره!
خلاصه اگر کسی میخواد بره سراغ پیشبینی اینکه کی وسط برنامه دیابت کم میاره، فعلاً هوش مصنوعی خیلی عب نداره، اما کمکم راه میافته. هنوزم کلید کار زده دست حمایت و یادگیری بیشتر از آدمهاس تا فقط امید به مدلهای هوش مصنوعی و عدد و رقم.
منبع: +


















