
تا حالا شده فکر کنین هوش مصنوعیها واقعاً چقدر میتونن تو زمینه پزشکی مخصوصاً نورولوژی (یعنی رشته مربوط به مغز و اعصاب) کمک کنن؟ این سؤال خیلی از دانشمندا بوده و اخیراً یه تیم از محققای اسرائیلی اومدن دقیقاً همینو بررسی کردن.
ماجرا از این قراره: هوش مصنوعیهایی مثل ChatGPT یا مدلهای زبان بزرگ (LLMها، یعنی مدلهایی که با حجم خیلی زیاد داده آموزش دیدن و میتونن متن رو بسازن و جواب بدن)، تو دنیای پزشکی کلی غوغا کردن. اما نورولوژی داستانش فرق داره. این حوزه پره از اصطلاحات عجیب و سوالای سختی که حتی برای متخصصا هم چالشه. مثلاً باید بتونی بفهمی دقیقاً کجای مغز آسیب دیده (که بهش میگن Anatomical Localization)، یا بعضی وقتا باید با یه سری علائم و نشونه، روند پیشرفت بیماری رو پیدا کنی (Temporal Pattern Recognition)، یا باید علائم رو درست تفسیر کنی که خیلی پیچیدهست.
این تیم تصمیم گرفتن ۳۰۵ تا سؤال از امتحان بورد نورولوژی اسرائیل رو جمع کنن و یه معیاری درست کنن تا ببینن مدلها واقعاً چقدر قویان. این سؤالها رو از سه نظر دستهبندی کردن: اینکه چقدر اطلاعات تخصصی میخواد، چقدر ترکیب مفاهیم پزشکی لازم داره، و اینکه سطح پیچیدگی منطق و استدلالش چقدره.
بعد اومدن ده تا مدل مختلف هوش مصنوعی رو امتحان کردن. بعضیا شون مدلهای پایه بودن، بعضیاشون با تکنیکای RAG بهتر شده بودن (RAG یعنی مدل میتونه هم از دیتابیس اطلاعات بگیره هم جواب بده – مثل وقتی داری همزمان تو گوگل سرچ میکنی و نوشتی رو هم با هم استفاده میکنی)، و یک روش خفنتر هم ساختن به اسم Multi-Agent (یعنی چندتا هوش مصنوعی که هر کدوم یه کار تخصصی انجام میدن و با هم همکاری میکنن تا جواب درست بدن).
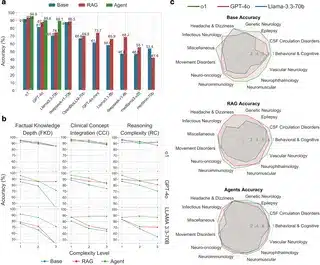
نتیجهها خیلی جالب بود! مدل OpenAI-o1 تونست بالاترین دقت رو تو جوابها بگیره (۹۰.۹٪ درستهها رو درست گفت)، اما مدلهایی که اسم پزشکی روشون بود مثل Meditron-70B، برعکس چیزی که فکر میکردن، بد عمل کردن (فقط ۵۲.۹٪ درست). تکنیک RAG هم واسه بعضی مدلها واقعا فرق داشت: مثلاً GPT-4o با این روش از ۸۰.۵٪ رسید به ۸۷.۳٪. اما هنوز تو سؤالهای خیلی سخت، حتی RAG هم نمیتونست کمک خاصی بکنه!
حالا روش چندعامله یا همون Multi-Agent اوضاع رو کامل عوض کرد. این سیستم جالب طوری طراحی شده بود که کل فرآیند حل سؤال رو به چند بخش مختلف تقسیم میکنه: اول سؤال رو دقیق آنالیز میکنه، بعد اطلاعات لازمو جمع میکنه، بعد جواب مینویسه، بعدش بررسی و اصلاحش میکنه – یعنی هر مأمور یه کار، همه کمک هم! با این روش، مثلا مدل LLaMA 3.3-70B که خودش دقتش ۶۹.۵٪ بود، تو حالت Multi-Agent شد ۸۹.۲٪! مخصوصاً تو سؤالهای سطخ بالا خیلی چشمگیر بود. خلاصه هر چی سؤال پیچیدهتر بود این سیستم بهتر خودشو نشون داد.
برای اینکه خیالشون راحت باشه، اومدن این روش رو روی یه دیتاست معروف دیگه امتحان کردن که اسمش MedQA هست (یه بانک سؤال پزشکی معروف جهان). جالبه که اونجا تکنیک RAG زیاد جواب نداد چون سوالاش عمومیتر بودن و به اطلاعات خاص مریضای نورولوژی ربط نداشت، اما تو همون سؤالهایی که خیلی به متنهای تخصصی نورولوژی نزدیک بود، باز Multi-Agent کولاک کرد.
خلاصه چی شد؟ این رویکرد چندعامله کاری کرد که اگه یه مدل تو یه گرایش نورولوژی (مثلاً بیماری حرکتی یا تشنج) ضعیف بود، دیگه نقطهضعفش از بین بره و تو همه دستهها عالی عمل کنه. یعنی هوش مصنوعی با یه تقسیم کار درست، تبدیل شد به یه دکتر همهفنحریف!
در نهایت، همه اینها باعث شد که محققا مطمئن بشن اگه هوش مصنوعی رو شبیه مغز متخصصا به چند بخش تقسیم کنیم و هر بخش روی یه مهارت خاص متمرکز شه، میتونه تو زمینههای خیلی پیچیده مثل نورولوژی هم کمک جدی به پزشکا بکنه. این خودش میتونه آینده جذابی برای هوش مصنوعی و پزشکی باشه و نشون میده که سیستمهای ساختاریافته چقدر میتونن کارآمدتر باشن.
منبع: +


















