
بذارین یه موضوع جالب رو خودمونی براتون توضیح بدم؛ داستان مدلهای زبانی بزرگ یا همون Large Language Models (LLMs)! اینها همون هوش مصنوعیهایی هستن که الان همه جا حرفشونه و مثلاً ChatGPT یکی از معروفتریناشونه. این مدلها میتونن تو کارهای حساس مثل پزشکی و سلامت خیلی به درد بخورن. ولی خب، یه سری ایراد دارن که اصلاً قابل چشمپوشی نیست!
خب ایرادها چیا هستن؟
اول اینکه این مدلها معمولاً با یه سری اطلاعات قدیمی تربیت شدن و نمیتونن بهروزرسانی بشن، یعنی اگه یه داروی جدید بیاد یا یه یافته جدید پیدا شه، مدل بیخبره! دوم اینکه بعضی وقتا اطلاعات اشتباه میدن و اصطلاحاً «هالوسینیت» میکنن؛ یعنی چیزی رو میسازن که اصلاً واقعی نیست! سومین مشکل اینه که هیچی هم نمیگن این جواب رو از کجا آوردن یا چطور بهش رسیدن. یعنی شفافیت صفر!
حالا اینجا یه تکنیک خیلی باحال میاد وسط به اسم Retrieval Augmented Generation یا خلاصهش RAG. منظور از RAG اینه که مدل رو به یه سری منبع اطلاعاتی خارجی وصل میکنن (مثلاً سایتها یا دیتابیس تخصصی)، و اول یه سرچی بین این منابع میزنه تا جواب دقیقتری بده و فقط گیر دادههای قدیمی خودش نباشه. خلاصه مثل این میمونه که یه آدم همهچیزدان رو با منبعهای جدید و کتابخونه وصله بزنی!
اما داستان RAG تو حوزه سلامت هنوز کامل جا نیفتاده. یعنی کسی دقیق نمیدونه کدوم دیتاستها (مجموعه داده)ها بهترن، چه مدلها و روشهایی برای RAG به درد میخوره، یا اصلاً چطور باید این کار رو دقیق ارزیابی کنیم؟ تازه، اون چارچوب یا Framework ارزیابی استاندارد هم نیست که همه طبق یه اصولی کار رو بسنجن. این مقاله اومده یه مروری بکنه و ببینه تا الان دانشمندا برای RAG و LLMها تو حوزه سلامت چیکار کردن، چه روشهایی خفنتر و چه ضعفهایی بوده.
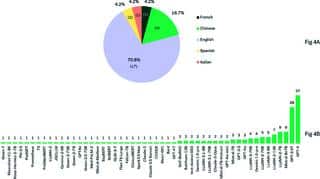
یکی از جالبترین چیزایی که تو این بررسی پیدا شده، اینکه حدود ۷۸/۹ درصد مطالعات از دیتاستهای انگلیسی استفاده کردن و فقط ۲۱/۱ درصد از دادههاشون چینی بودن. خلاصه، هنوزم زبان انگلیسی حکومت میکنه تو این حوزه!
حالا مدلهایی که برای RAG تو سلامت رایج هستن چیان؟ سه گروه اصلی داریم: Naive RAG که خیلی ساده و پایه است، Advanced RAG که یکم شاخ و حرفهایتره، و Modular RAG که قسمت به قسمت و ماژولار همه چی رو جمعوجور میکنه. جالب تر اینکه مدلهای معروف و اصطلاحاً Proprietary مثل GPT-3.5 و GPT-4 (اونهایی که شرکت OpenAI ساخته و آزاد نیستن!) بیشتر از بقیه استفاده شدن. انگار همه طرفدار راحتی و قدرت این مدلها هستن!
ولی یه مشکل بزرگ هست و اون هم نبود یه روش استاندارد برای ارزیابی این سیستمهاست؛ یعنی هرکسی یه جوری خودش میسنجتشون! این باعث میشه مقایسهشون با هم تقریباً نشدنی باشه.
یه نکته خیلی مهم دیگه هم هست: اکثر این مطالعات اصلاً حواسشون به بحث اخلاقی نیست! مثلاً مسائل حفظ حریم خصوصی یا اشتباهات مرگبار پزشکی که میتونه پیش بیاد. یعنی موضوعات حساس مثل این رو یا بررسی نکردن یا برنامهای واسش ندارن. Ethical considerations یعنی همین دغدغههای اخلاقی.
پس اگه بخوام خلاصه کنم: RAG میتونه مدلها رو خیلی باهوشتر و بهروزتر کنه، اما هنوز جای پیشرفت داره. مخصوصاً تو بحث اخلاق و اینکه چطور عملکردشو بشه دقیقتر ارزیابی کرد. به قول نویسندهها، هنوز کلی پژوهش و کار باقی مونده تا این فناوری رو بشه واقعاً مسئولانه و با خیال راحت تو بیمارستانها و کلینیکها استفاده کرد.
در کل، اگه از دنیای هوش مصنوعی تو پزشکی خوشت میاد و دنبال راههایی هستی که مشکلات «اطلاعات قدیمی»، «هالوسینیشن» و شفافیت مدلها حل شه، RAG گزینه خیلی امیدبخشی به نظر میاد! فقط باید حسابی روش کار کنیم تا مطمئن بشیم مشکلات جدیدتری درست نمیکنه.
منبع: +


















