
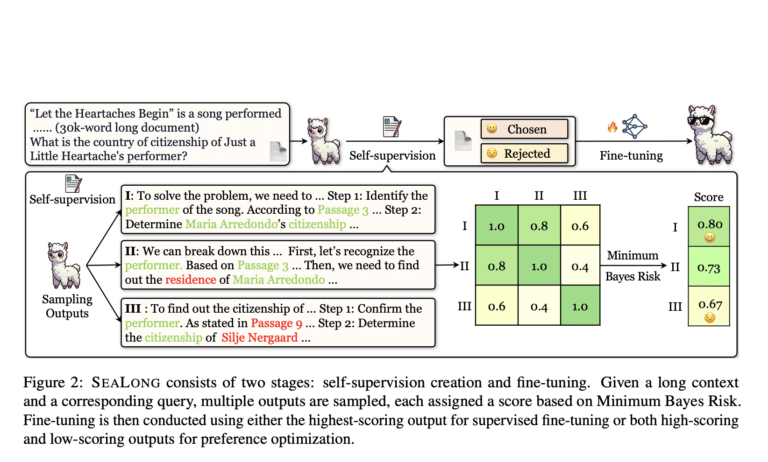
SEALONG یک روش خودبهبوددهندهی نوآورانه است که عملکرد استدلال متنمحور مدلهای زبانی بزرگ را در مواجهه با متون طولانی ارتقاء میدهد. این روش با استفاده از تکنیکهایی مانند امتیازدهی ریسک حداقل بیز (Minimum Bayes Risk: MBR) و خودآموزی، بدون نیاز به حاشیهنویسیهای خارجی، تحول چشمگیری در توانایی درک متنی مدلهای هوش مصنوعی به وجود آورده است.
SEALONG: یک رویکرد خودبهبود دهنده برای استدلال مبتنی بر متن طولانی
مدلهای زبانی بزرگ (LLMs) چشمانداز فناوری را به ویژه در حوزههایی که نیازمند درک متنی گسترده هستند، متحول کردهاند. از کمک به کدنویسی در سطح مخزن گرفته تا تحلیل چند سند و توسعه عاملهای خودکار، این مدلها سازگاری قابل توجهی را نشان میدهند. با این حال، استدلال مبتنی بر متن طولانی همچنان یک مرز چالش برانگیز است. در حالی که LLMs در کارهای ساده مانند یافتن اطلاعات خاص در مجموعه دادههای عظیم برتری دارند، عملکرد آنها اغلب در مواجهه با چالشهای استدلالی پیچیدهتر دچار مشکل میشود. این ناسازگاری، نیاز مبرم به راهحلهای نوآورانه برای تقویت درک متنی در سیستمهای هوش مصنوعی را برجسته میکند.
چالشهای استدلال مبتنی بر متن طولانی
LLMs موجود با دو مسئله اساسی روبرو هستند:
– تکهتکه شدن متنی: مدیریت اطلاعات پراکنده در ورودیهای طولانی اغلب منجر به خروجیهای ناقص یا نامربوط میشود.
– متغیر بودن استدلال: در حالی که مدلها میتوانند در کارهای بازیابی ساده به دقت بالایی دست یابند، عملکرد آنها هنگام استدلالی که نیاز به ادغام متنی عمیقتر دارد، کاهش مییابد.
این چالشها اهمیت پیشرفت هم در معماری و هم در روشهای آموزش LLMs را برای ایجاد خروجیهای سازگارتر و قابل اعتمادتر برجسته میکند.
رویکردهای کلیدی برای بهبود پردازش متن طولانی
تحقیقات کنونی در مورد بهبود قابلیتهای متن طولانی LLMs به دو دسته اصلی تقسیم میشود:
1. استراتژیهای مدلمحور
– اصلاحات در تعبیههای موقعیت و مکانیسمهای توجه.
– نوآوریهای معماری با هدف بهبود کارایی محاسباتی و درک متنی.
- استراتژیهای دادهمحور
- آموزشهای پیشرفته مداوم بر روی مجموعه دادههای دنبالهای گسترده.
- استفاده از خروجیهای مدل متخصص یا حاشیهنویسیهای انسانی برای گردآوری دادههای آموزشی با کیفیت بالا.
هر دو مسیر نتایج امیدوارکنندهای به همراه داشتهاند، اما اغلب نیازمند مداخلات منابع فشرده مانند برچسبگذاری گسترده یا بازنگریهای معماری هستند.
معرفی SEALONG: یک راهحل خودآموز
محققان مؤسسات برجسته، از جمله دانشگاه چینی هنگ کنگ و تنسنت، SEALONG را پیشنهاد دادهاند، یک روش خودبهبود دهندهی جدید که برای افزایش استدلال مبتنی بر متن طولانی در LLMs طراحی شده است. SEALONG چالشهای مهمی مانند توهم و ناهماهنگی استدلال را از طریق یک فرآیند بهینهسازی دو مرحلهای برطرف میکند:
- نمونهبرداری مسیر استدلال
- برای هر ورودی، مدل چندین مسیر استدلال ایجاد میکند.
- خروجیها بر اساس سازگاری معنایی و شباهت تعبیه با استفاده از امتیازدهی ریسک حداقل بیز (MBR) ارزیابی میشوند.
-
مسیرهایی با نمرات سازگاری بالاتر در اولویت قرار میگیرند و خطر پاسخهای توهمزا را کاهش میدهند.
-
بهینهسازی از طریق خودآموزی
- تنظیم دقیق نظارت شده: خروجیهای با امتیاز بالا برای اصلاح فرآیندهای استدلال مدل استفاده میشوند.
- بهینهسازی ترجیح: هر دو مسیر با امتیاز بالا و پایین، توانایی مدل را برای تمایز بین مسیرهای استدلال قابل اعتماد و غیرقابل اعتماد افزایش میدهند.
این چارچوب خودآموز به SEALONG اجازه میدهد تا قابلیتهای استدلال خود را بدون تکیه بر حاشیهنویسیهای انسانی خارجی یا مداخلات متخصص افزایش دهد و آن را به یک راهحل مقرون به صرفه و مقсштаپذیر تبدیل کند.
نتایج تجربی
SEALONG در LLMs های پیشرو مختلف آزمایش شد و پیشرفتهای قابل توجهی را در وظایف استدلال متن طولانی نشان داد. یافتههای کلیدی عبارتند از:
– افزایش دقت در وظایفی که نیاز به ادغام متنی عمیق دارند.
– کاهش اتکا به حاشیهنویسیهای خارجی، سادهسازی فرآیند آموزش مدل.
– بهبود سازگاری معنایی، منجر به خروجیهای قابل اعتمادتر در سناریوهای مختلف.
این نتایج، پتانسیل SEALONG را برای تعریف مجدد مرزهای آنچه LLMs میتوانند در زمینههای استدلال پیچیده به دست آورند، برجسته میکند.
پیامدها برای توسعه هوش مصنوعی
معرفی SEALONG پیشرفت محملی را در تحقیقات هوش مصنوعی نشان میدهد و مسیری مقیاسپذیر برای بهبود استدلال مبتنی بر متن طولانی بدون منابع خارجی گسترده ارائه میدهد. با فعال کردن مدلها برای اصلاح فرآیندهای استدلال خود به طور خودکار، SEALONG نه تنها قابلیتهای فعلی را افزایش میدهد، بلکه زمینه را برای نوآوریهای آینده در هوش مصنوعی فراهم میکند.
کاربردهای بالقوه عبارتند از:
– کمک تحقیقاتی پیشرفته: مدیریت سنتز چند سند برای موارد استفاده دانشگاهی و حرفهای.
– عاملهای خودکار: فعال کردن تصمیمگیری قابل اعتمادتر در محیطهای پویا.
– وظایف کدنویسی پیچیده: ارائه پشتیبانی مداوم برای چالشهای برنامهنویسی در سطح مخزن.
چشماندازی برای آینده
SEALONG گامی مهم در جهت پر کردن شکاف بین قابلیتهای هوش مصنوعی فعلی و استدلال شبیه انسان است. رویکرد خودآموز آن با روند گستردهتر ایجاد سیستمهای هوش مصنوعی خودکارتر، کارآمدتر و آگاه از متن همسو است. همانطور که محققان به ساختن بر روی این پایه ادامه میدهند، پتانسیل هوش مصنوعی برای متحول کردن صنایع و پرداختن به چالشهای پیچیده جهانی به طور فزایندهای ملموس میشود.
با اولویت دادن به نوآوری در استدلال مبتنی بر متن طولانی، SEALONG نه تنها محدودیتهای موجود را برطرف میکند، بلکه مسیرهای جدیدی را برای کاوش باز میکند و تضمین میکند که مدلهای زبانی بزرگ در خط مقدم پیشرفت فناوری باقی میمانند.
اگر به خواندن کامل این مطلب علاقهمندید، روی لینک مقابل کلیک کنید: marktechpost.com









")







")

