
Xmodel-1.5، یک مدل زبانی بزرگ چندزبانه جدید با ۱ میلیارد پارامتر، عملکرد بسیار خوبی در زبانهای کممنبع مانند تایلندی و عربی دارد. این مدل زبانی قدرتمند که با ۲ تریلیون توکن آموزش داده شده است، شکافهای ارتباطی را در میان چشماندازهای زبانی متنوع پر میکند.
Xmodel-1.5 یک مدل زبانی بزرگ (LLM) چندزبانه پیشرفته با ۱ میلیارد پارامتر است که توسط آزمایشگاه هوش مصنوعی شرکت Xiaoduo Technology توسعه داده شده است. این مدل که با ۲ تریلیون توکن آموزش داده شده، هم در زبانهای پرمنبع مانند انگلیسی و چینی و هم به طور قابل توجهی در زبانهای کممنبع مانند تایلندی، عربی، فرانسوی و غیره عملکرد بسیار خوبی دارد. این تمرکز بر فراگیری برای جوامع زبانی کمنماینده، Xmodel-1.5 را متمایز میکند و شکاف مهمی را در قابلیتهای فعلی پردازش زبان طبیعی (NLP) برطرف میسازد.
قدرت این مدل در توانایی آن در درک و تولید متن در طیف وسیعی از زبانها نهفته است و بر محدودیتهایی که اغلب در مدلهای NLP سنتی که با زبانهای کمتر رایج مشکل دارند، غلبه میکند. این پیشرفت در دنیای بههمپیوسته امروزی که ارتباطات بین زبانی موثر بهطور فزایندهای ضروری است، بسیار مهم است.
قدرت فنی و آموزش
Xmodel-1.5 از ترکیبی پیچیده از تکنیکها و انتخابهای معماری بهره میبرد. این مدل از یک توکنساز تکواژهای (unigram tokenizer) که بهطور خاص برای برنامههای چندزبانه آموزش داده شده است، با واژگانی از ۶۵۲۸۰ توکن استفاده میکند. این توکنساز، کارایی را با پوشش زبانی گسترده متعادل میکند و ظرافتهای زبانهای مختلف، از جمله زبانهایی با املا کمتر استاندارد را در خود جای میدهد.
معماری این مدل شامل چندین ویژگی کلیدی است:
- جاسازی موقعیتی چرخشی (Rotary Positional Embedding – RoPE): درک مدل از ترتیب کلمات و بافت را در زبانهای مختلف افزایش میدهد.
- نرمالسازی RMS (RMS Normalization): پایداری آموزش را بهبود میبخشد و به مدل اجازه میدهد تا بهطور موثرتری از مجموعه دادههای وسیع یاد بگیرد.
- تابع فعالسازی SwiGLU (SwiGLU Activation): عملکرد را بهینه میکند و منجر به پردازش سریعتر و دقیقتر میشود.
- توجه کوئری گروهبندی شده (Grouped-Query Attention): کارایی آموزش و استنتاج را افزایش میدهد و مدل را برای کاربردهای دنیای واقعی عملیتر میکند.
دادههای آموزشی برای Xmodel-1.5 بهطور قابل توجهی متنوع هستند و از منابعی مانند Multilang Wiki، CulturaX و مجموعه دادههای خاص زبانهای مختلف گرفته شدهاند. این پیکره متنوع، همراه با یک رویکرد توزیع داده استراتژیک، نمایش کافی از زبانهای کممنبع را تضمین میکند و از سوگیری مدل به سمت زبانهای رایجتر جلوگیری میکند. مجموعه دادههای ۲ تریلیون توکنی، توانایی مدل را برای تعمیم خوب در میان چشماندازهای زبانی مختلف تقویت میکند. پس از آموزش، تنظیم دقیق دستورالعملها اجرا شد که بهطور قابل توجهی مهارت مدل را بهویژه در وظایف تولید مبتنی بر بازیابی (retrieval-augmented generation – RAG) در حوزه تجارت الکترونیک بهبود بخشید و به نرخ رضایتمندی قابل توجه ۹۲.۴۷٪ دست یافت.
عملکرد معیار و اهمیت
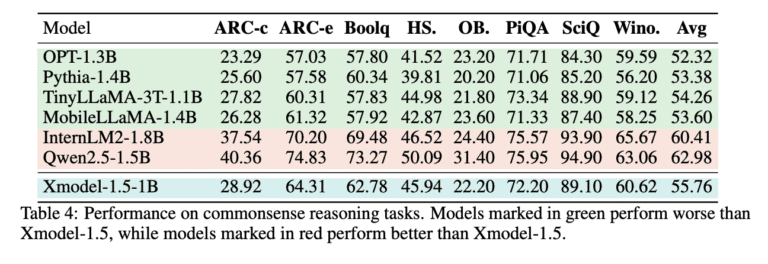
Xmodel-1.5 در مقایسه با مدلهای پایه مانند OPT، Pythia و TinyLLaMA، بهویژه در وظایف استدلال عقل سلیم در چندین زبان، عملکرد برتری را نشان داده است. در معیارهای چندزبانه، از جمله ARC، XCOPA و mMMLU، از PolyLM-1.7B پیشی میگیرد. عملکرد مدل در نسخه عربی HellaSwag و زیرمجموعه تایلندی معیار Belebele، اثربخشی آن را در مدیریت ورودیهای زبانی متنوع بیشتر نشان میدهد.
انتشار یک مجموعه داده ارزیابی تایلندی، که توسط دانشجویان دانشکده نوآوری یکپارچه دانشگاه Chulalongkorn حاشیهنویسی شده است، تعهد این پروژه را به پیشبرد تحقیقات NLP چندزبانه بیشتر نشان میدهد. این مجموعه داده، معیار ارزشمندی را برای تحقیق و توسعه آینده در درک زبان کممنبع فراهم میکند.
پر کردن شکاف زبانی
Xmodel-1.5 گامی مهم در جهت پر کردن شکاف ارتباطی بین زبانها و فرهنگهای مختلف است. تمرکز آن بر فراگیری، بهویژه برای جوامع زبانی کمنماینده، جنبه مهمی از سهم آن در حوزه NLP است. Xmodel-1.5 با ارائه یک ابزار قدرتمند و همهکاره برای پردازش چندزبانه، محققان و توسعهدهندگان را قادر میسازد تا برنامههای فراگیرتر و موثرتری بسازند که پاسخگوی مخاطبان جهانی باشد. در دسترس بودن آزاد آن، دسترسی به آن را بهعنوان یک منبع ارزشمند برای کاربردهای دانشگاهی و عملی تضمین میکند. با ادامه رشد تعاملات بین فرهنگی، مدلهایی مانند Xmodel-1.5 نقش حیاتی در تقویت درک و ارتباط بهتر در میان موانع زبانی ایفا خواهند کرد. این پیشرفت نه تنها نشاندهنده یک دستاورد فناوری است، بلکه گامی مهم به سوی آیندهای متصلتر و فراگیرتر است.
اگر به خواندن کامل این مطلب علاقهمندید، روی لینک مقابل کلیک کنید: marktechpost.com

")
")











")




