
میخواهید یک موتور جستجوی مولد محلی داشته باشید؟ یاد بگیرید چطور به راحتی با VerifAI، یک موتور جستجوی مولد محلی راهاندازی کنید. این پروژه متنباز به شما این امکان را میدهد تا با استفاده از مدلهای پیشرفته هوش مصنوعی، بر اساس فایلهای محلی خودتان، یک موتور جستجوی سفارشی ایجاد کنید.
VerifAI یک پروژه متنباز است که به کاربران این امکان را میدهد تا یک موتور جستجوی مولد سفارشی بر اساس فایلهای محلی خود ایجاد کنند. این ابزار نوآورانه از قدرت مدلهای پیشرفته هوش مصنوعی بهره میبرد و کاربران را قادر میسازد تا اسناد شخصی یا سازمانی خود را با زبان طبیعی جستجو کرده و پاسخهای دقیق و ارجاعدار دریافت کنند. چه برای بهرهوری شخصی و چه برای مدیریت دانش در سطح سازمانی، VerifAI یک راهکار قوی و چندمنظوره ارائه میدهد.
این نسخه بهروز شده، VerifAI Core، بر پایه VerifAI BioMed اولیه که بر حوزه پزشکی تمرکز داشت، ساخته شده است. در حالی که VerifAI BioMed برای جستجوهای تخصصی پزشکی همچنان در دسترس است، VerifAI Core این قابلیت را به هر نوع فایلی گسترده میکند و کاربرد آن را به طیف وسیعتری از موارد استفاده افزایش میدهد.
معماری و عملکرد:
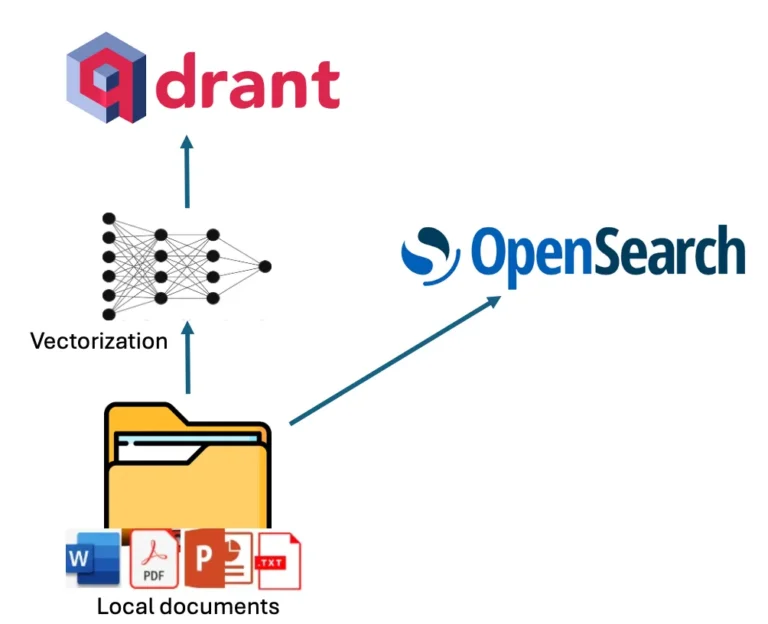
معماری VerifAI از سه جزء اصلی تشکیل شده است: نمایهسازی، تولید تقویتشده با بازیابی (Retrieval-Augmented Generation – RAG) و یک موتور تایید منحصر به فرد. فرآیند نمایهسازی از یک رویکرد دوگانه استفاده میکند که نمایهسازی لغوی و معنایی را برای پوشش جامع ترکیب میکند.
- نمایهسازی لغوی (Lexical Indexing): از OpenSearch برای نمایهسازی متن لفظی در اسناد استفاده میکند و جستجوی سنتی مبتنی بر کلمه کلیدی را امکانپذیر میسازد.
- نمایهسازی معنایی (Semantic Indexing): از یک مدل تعبیهسازی (از Hugging Face) برای ثبت معنی و زمینه بخشهای سند استفاده میکند و این نمایشهای برداری را در Qdrant ذخیره میکند. این امر امکان جستجوهای ظریفتر بر اساس شباهت مفهومی به جای تطبیق صرف کلمات کلیدی را فراهم میکند.
هنگامی که کاربر سوالی مطرح میکند، VerifAI پرس و جو را از طریق کانالهای لغوی و معنایی پردازش میکند. OpenSearch اسناد را بر اساس تطابق کلمات کلیدی بازیابی میکند، در حالی که Qdrant اسناد مشابه از نظر معنایی را با استفاده از مقایسههای برداری شناسایی میکند. سپس نتایج هر دو موتور ادغام و بر اساس امتیاز ارتباط ترکیبی رتبهبندی میشوند.
اسناد انتخاب شده، همراه با سوال کاربر و دستورالعملهای خاص، یک ورودی (prompt) دقیق برای یک مدل زبانی بزرگ (Large Language Model – LLM) تشکیل میدهند. کاربر میتواند LLM مورد استفاده را پیکربندی کند و از بین مدلهای خود-میزبان مانند Mistral و Llama 2 یا گزینههای تجاری مانند GPT-4 یکی را انتخاب کند. اگر هیچ مدلی مشخص نشده باشد، VerifAI به طور پیشفرض از یک مدل Mistral تنظیمشده و مستقر محلی استفاده میکند.
در نهایت، موتور تایید منحصر به فرد VerifAI پاسخ LLM را تجزیه و تحلیل میکند و آن را با اسناد منبع بررسی میکند تا از دقت اطمینان حاصل کرده و توهم (اطلاعات نادرست یا ساختگی) را به حداقل برساند. این مرحله حیاتی، قابلیت اطمینان پاسخهای تولید شده را افزایش میدهد و اطلاعات قابل اعتماد و تایید را در اختیار کاربران قرار میدهد.
نصب و راهاندازی:
استقرار VerifAI به صورت محلی شامل چندین مرحله است که با شبیهسازی مخزن و راهاندازی یک محیط پایتون آغاز میشود. کاربران باید کتابخانههای مورد نیاز را نصب کرده و دسترسی به اجزای مختلف، از جمله پایگاه داده PostgreSQL، OpenSearch، Qdrant و LLM انتخاب شده را پیکربندی کنند. یک فایل محیطی این فرآیند پیکربندی را ساده میکند و به کاربران اجازه میدهد پارامترهایی مانند کلیدهای API، اعتبارنامههای پایگاه داده و مسیرهای مدل را مشخص کنند.
پس از پیکربندی سیستم، کاربران باید فروشگاههای داده لازم (OpenSearch، Qdrant و PostgreSQL) را با استفاده از یک اسکریپت ارائه شده نصب کنند. این اسکریپت فرآیند راهاندازی را خودکار میکند و شروع کار را برای کاربران آسانتر میکند. در نهایت، کاربران میتوانند فایلهای محلی خود را با هدایت اسکریپت نمایهسازی VerifAI به دایرکتوری مورد نظر، نمایهسازی کنند. این سیستم از فرمتهای مختلف فایل، از جمله PDF، Word، PowerPoint، متن و Markdown پشتیبانی میکند.
پس از اتمام نمایهسازی، کاربران میتوانند backend و frontend VerifAI را اجرا کنند. backend، که توسط FastAPI پشتیبانی میشود، ارتباط بین اجزای مختلف را مدیریت میکند، در حالی که frontend، که با React.js ساخته شده است، یک رابط کاربرپسند برای تعامل با موتور جستجو فراهم میکند.
ویژگیها و مزایای کلیدی:
- استقرار محلی (Local Deployment): حریم خصوصی و کنترل دادهها را تضمین میکند، زیرا تمام پردازشها روی دستگاه کاربر انجام میشود.
- LLM قابل تنظیم (Customizable LLM): به کاربران اجازه میدهد مناسبترین LLM را برای نیازها و منابع خود انتخاب کنند.
- رویکرد نمایهسازی دوگانه (Dual Indexing Approach): جستجوی لغوی و معنایی را برای نتایج جامع و دقیق ترکیب میکند.
- موتور تایید (Verification Engine): توهم را به حداقل میرساند و قابلیت اطمینان پاسخهای تولید شده را تضمین میکند.
- متنباز (Open Source): مشارکتهای جامعه و توسعههای آینده را تشویق میکند.
- پشتیبانی از فایلهای متنوع (Versatile File Support): فرمتهای مختلف سند را نمایهسازی میکند و آن را برای موارد استفاده متنوع مناسب میسازد.
VerifAI یک راهکار قدرتمند و انعطافپذیر برای ساخت یک موتور جستجوی مولد محلی ارائه میدهد. ماهیت متنباز آن، همراه با ویژگیهای پیشرفته و سهولت استقرار، آن را به گزینهای جذاب برای افراد و سازمانهایی تبدیل میکند که به دنبال رهاسازی پتانسیل دادههای محلی خود هستند.
اگر به خواندن کامل این مطلب علاقهمندید، روی لینک مقابل کلیک کنید: towardsdatascience.com



















